LSM-Tree 이해하기: 키-값 데이터베이스에서 쓰기 성능 최적화
01 Jan 2024개요
데이터 중심 애플리케이션 책의 저장소 엔진 파트에 대한 독후감을 겸해서 주로 Key-Value 기반의 스토리지 엔진에서 사용되는 LSM 트리의 기본 개념과 쓰기에 효율적인 이유들을 알아봅니다.
여러 스토리지 엔진들의 문서들을 볼 때 후술할 SS-Table이 언급된다면 LSM 트리를 사용하고 있다고 볼 수 있습니다.
LSM-Tree(Log-structured merge-tree)의 구조와 쓰기 효율성
LSM 트리는 대규모 쓰기 연산에 최적화된 데이터 저장 구조입니다. 이 구조는 쓰기 연산의 효율성을 극대화합니다.
Memtable의 역할
데이터 쓰기는 먼저 Memtable에 이루어집니다. 이 때 Memtable은 메모리에 존재하여 디스크 I/O 대비 매우 빠른 쓰기를 보장합니다.
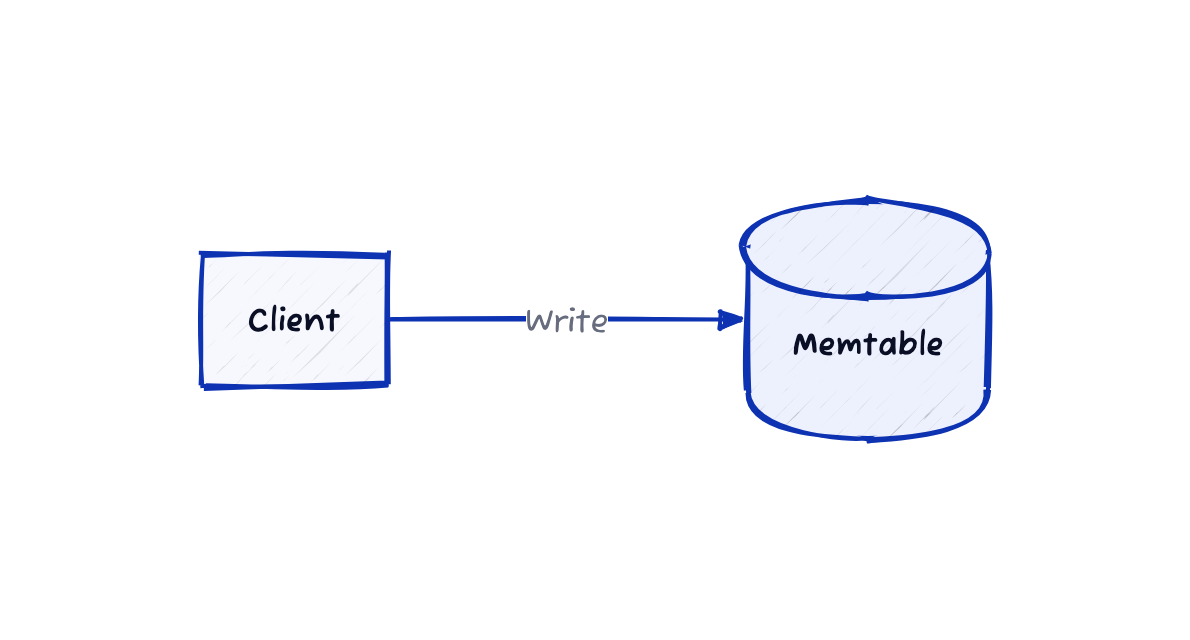
Memtable에서는 Key가 정렬된 상태로 저장되어야 하며, 이를 위해 Red-Black Tree, Skip List, 혹은 AVL Tree와 같은 균형 이진 탐색 트리가 사용될 수 있습니다.
SS-Table과 디스크 저장
Memtable이 설정된 임계값에 도달하면, 그 내용은 디스크에 파일로 저장됩니다. 이 파일을 SS-Table(=Sorted String Table)이라고 부릅니다.
SS-Table은 이름처럼 정렬되어 있기 때문에 범위(Range) 검색이나 순차 I/O에 효율적입니다.
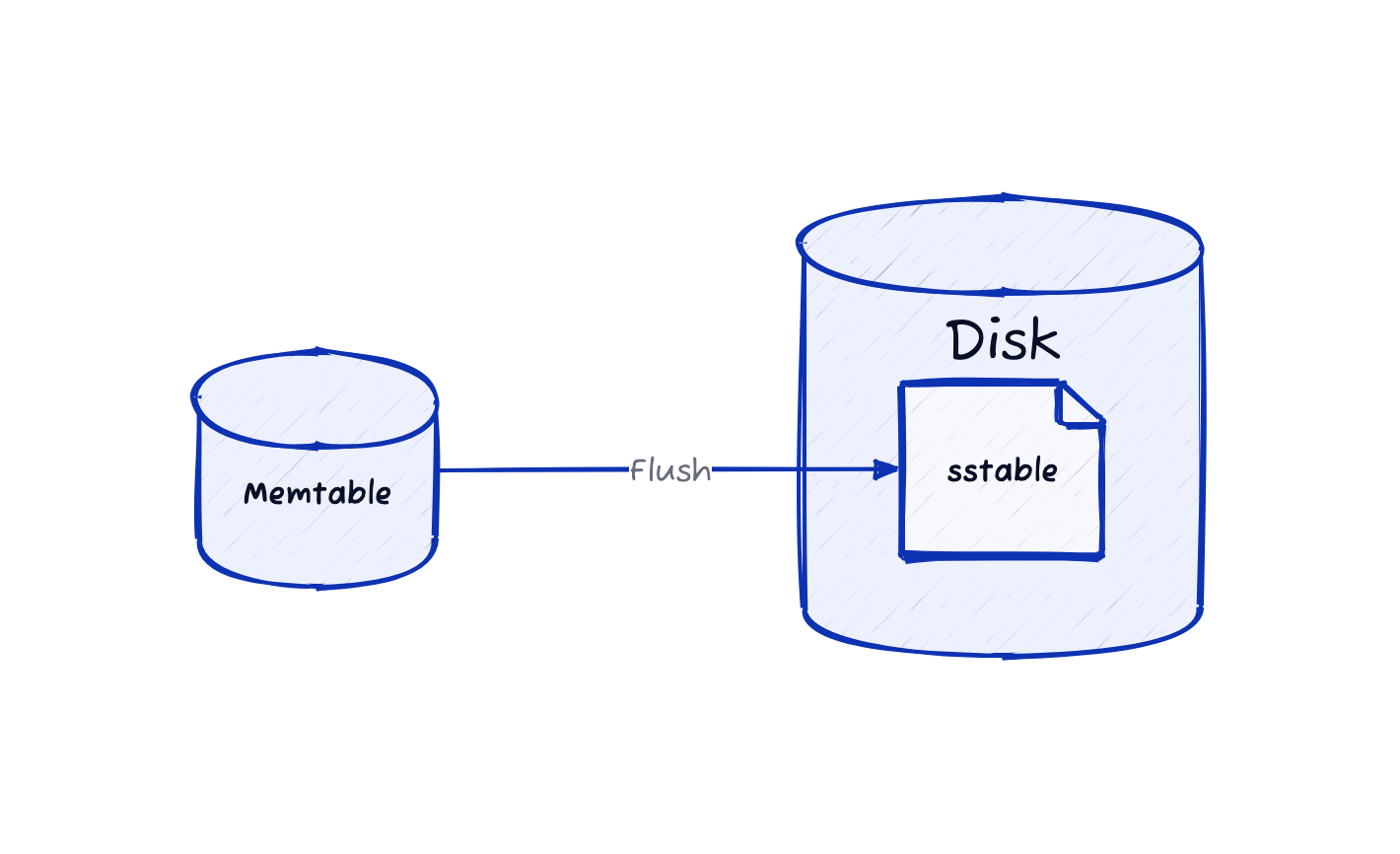
SS-Table은 불변성을 지니며, 한 번 기록된 후에는 변경되지 않습니다. 이 구조는 데이터 일관성을 보장하며 압축이 진행되는 중에도 쓰기 연산을 지속할 수 있도록 합니다.
또한 장애 발생 시 SS-Table은 복구를 위한 기반 데이터로 사용됩니다.
압축(Compaction)과 최적화
Memtable이 지속적으로 디스크에 Flush되어 SS-Table이 임계치를 넘어서면 LSM 트리는 백그라운드에서 압축 과정을 수행합니다.
이 과정은 중복 데이터를 제거하여 파일 크기를 줄이지만, 새로운 SS-Table을 생성하므로 쓰기 증폭(Write throughput)을 초래합니다.
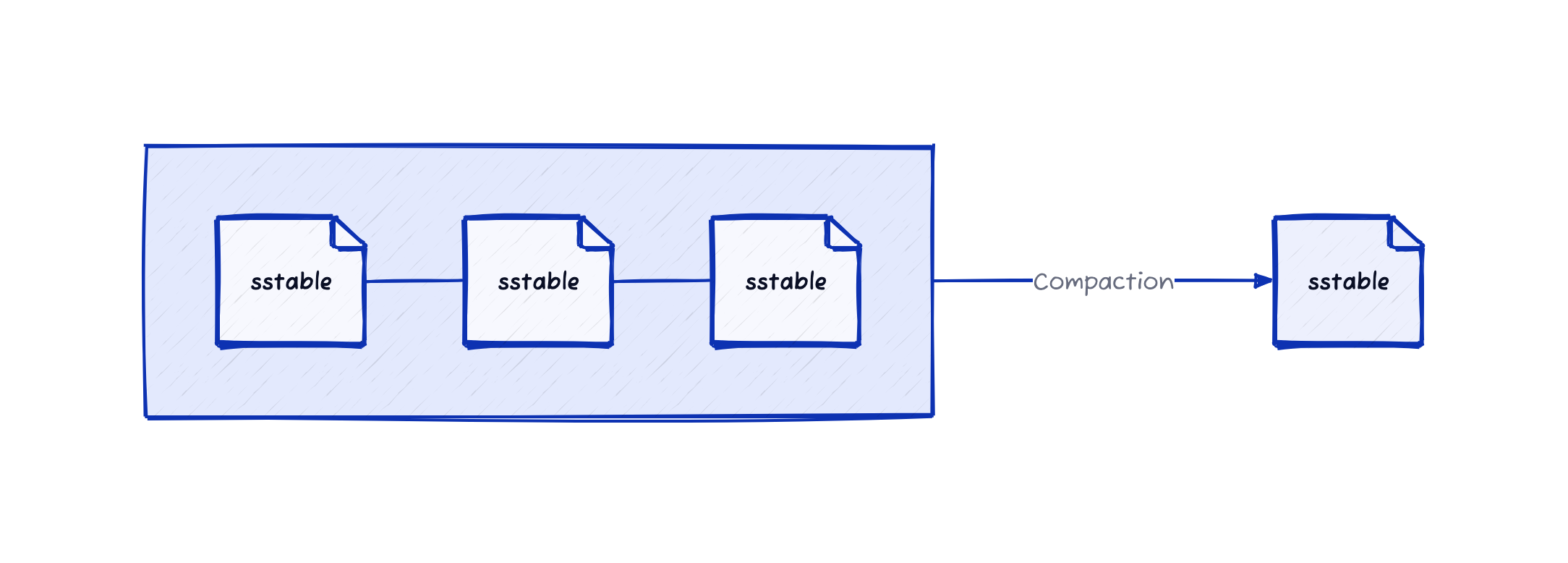
압축 알고리즘은 보통 크기 계층 압축과 레벨 기반 압축으로 나뉩니다.
크기 계층 압축(Size-Tiered Compaction)
이 방식은 SS-Table의 크기를 기준으로 병합합니다.
- SS-Table 생성: Memtable이 가득 차면, 그 내용을 디스크에 Flush하여 새로운 SS-Table을 생성합니다.
- 병합 검토: 새 SS-Table이 생성될 때마다, 시스템은 크기가 비슷한 기존 SS-Table을 검토합니다. 크기가 유사한 SS-Table이 없으면 병합을 하지 않습니다.
- 병합 실행: 적절한 병합 대상이 있으면, 시스템은 이들을 하나의 큰 SS-Table로 병합합니다.
- SS-Table 갱신: 병합 과정을 통해 새로운 SS-Table이 생성되고, 병합에 사용된 기존 SS-Table은 삭제됩니다.
- 반복: 이 과정은 데이터베이스에서 지속적으로 반복되어, 데이터 관리를 최적화하고 쓰기 부담을 줄입니다.
이 전략은 큰 단위로 압축이 이루어지기 때문에 쓰기 증폭(Write Amplification)을 최소화하는데 도움이 되지만, 큰 SS-Table의 병합은 많은 시간과 자원을 요구합니다. 또한, 쓰기 작업이 자주 일어나지 않는 경우 병합 대상이 없어 압축이 이루어지지 않고 SS-Table의 수만 증가하게 되어 읽기 성능이 저하될 수 있습니다.
그리고 레벨 기반 압축에 비해 읽기 성능은 떨어질 수 있습니다. (이유는 후술)
레벨 기반 압축(Level-Based Compaction)
이 방식은 SS-Table을 레벨에 따라 분류하고, 레벨별로 병합을 수행합니다.
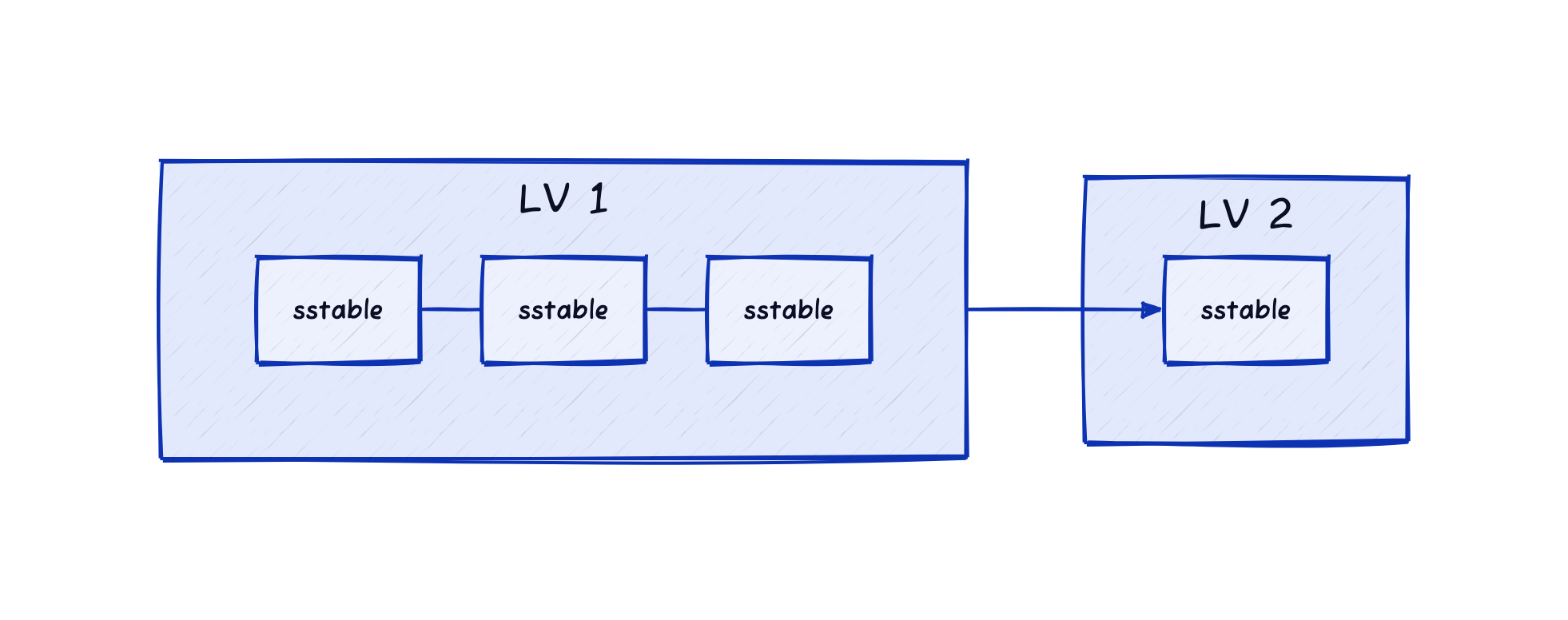
- SS-Table 생성: Memtable이 Flush되면, 생성된 SS-Table은 데이터베이스의 가장 낮은 레벨인 LV 1에 저장됩니다.
- 병합 조건 확인: LV 1의 SS-Table 개수가 임계치에 도달하면, 병합 대상으로 선정됩니다.
- 병합 및 레벨 이동: 병합된 SS-Table은 다음 레벨인 LV 2로 이동하고, 기존 SS-Table은 삭제됩니다.
- 레벨별 반복: 이 과정은 계속해서 더 높은 레벨로 진행되며, 최고 레벨 LV N에 이르기까지 반복됩니다.
- 최종 레벨 처리: 최고 레벨 LV N에 도달하면, 추가적인 레벨 증가 없이 해당 레벨에서만 병합이 진행됩니다.
일반적으로 높은 레벨로 갈수록 SS-Table의 크기는 커지며, 병합에 소요되는 시간과 자원은 증가합니다.
주로 작은 단위로 압축이 자주 이루어지기 때문에 쓰기 증폭(Write throughput)이 커질 수 있지만, 크기 계층 압축에 비해 읽기 성능은 향상될 수 있습니다. (이유는 후술)
LSM 트리의 읽기 과정과 블룸 필터의 역할
LSM 트리는 쓰기에 효율적이지만, B-Tree 기반 RDB에 비해 읽기가 상대적으로 느립니다. 이해를 위해 LSM 트리의 읽기 과정과 블룸 필터의 역할을 살펴봅시다.
읽기 과정
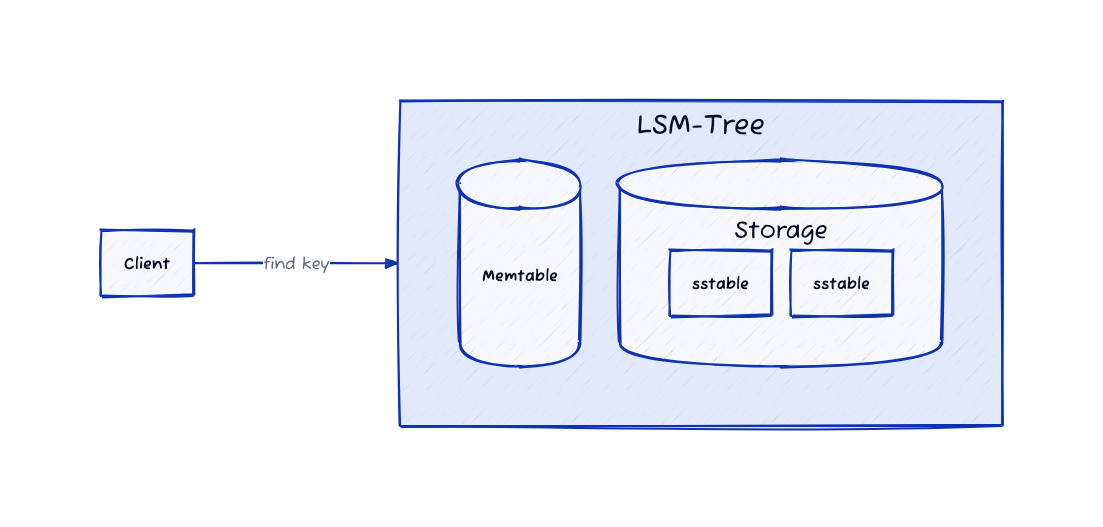
- Memtable 검색: 메모리 내 Memtable에서 요청된 키를 빠르게 검색합니다.
- SS-Table 검색: Memtable에서 키를 찾지 못할 경우, 디스크 상의 정렬된 SS-Table들을 검색합니다. 이 단계는 디스크 I/O를 필요로 하므로, Memtable 검색보다 시간이 더 소요됩니다.
- 결과 반환: 키에 대한 값을 찾으면 반환하고, 찾지 못하면 데이터가 없는 것으로 간주합니다.
블룸 필터(Bloom Filter)
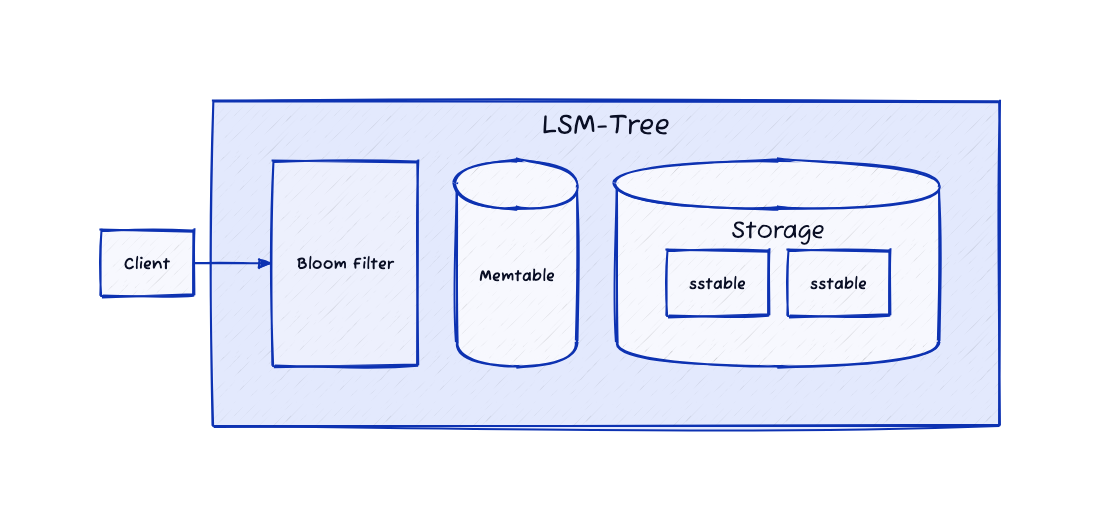
- 효율성 증대: 많은 수의 SS-Table이 존재할 경우, 블룸 필터를 사용하여 키의 존재 여부를 먼저 확인합니다. 이는 키가 없는 경우 불필요한 디스크 I/O를 방지하여 읽기 과정의 효율성을 높입니다.
블룸 필터의 사용은 LSM 트리의 읽기 과정을 최적화하여, SS-Table의 수가 많아도 효율적인 데이터 검색을 가능하게 합니다.
레벨 기반 압축과 크기 계층 압축을 사용하는 LSM 트리의 읽기 과정을 간략화하면 다음과 같습니다
크기 계층 압축에서의 읽기
데이터는 크기별로 그룹화된 단일 레벨에 저장됩니다. 읽기 시, 모든 SS-Table을 탐색할 수 있습니다.
키가 여러 SS-Table에 분산될 수 있어 필요한 I/O 작업이 많아져 읽기가 덜 효율적일 수 있습니다.
레벨 기반 압축에서의 읽기
데이터는 여러 레벨에 걸쳐 오름차순으로 정렬되어 저장됩니다. 읽기 시, 낮은 레벨부터 키를 찾습니다.
잘 정렬된 데이터와 중복 최소화로 인해 필요한 I/O 작업이 적어, 읽기가 빠르고 효율적입니다. (시간 지역성에 의해서 낮은 레벨에 필요한 데이터가 있을 확률이 높습니다.)
레벨 기반 압축은 읽기 성능이 더 우수하며, 크기 계층 압축은 더 많은 디스크 I/O로 인해 읽기가 느려질 수 있습니다.
결론
LSM 트리는 쓰기 작업에 최적화된 데이터베이스 구조로, 특히 쓰기가 빈번한 애플리케이션에 적합합니다. 이는 Memtable이 메모리에 위치하여 빠른 쓰기를 가능하게 하고, SS-Table을 디스크에 저장함으로써 데이터의 일관성을 보장하기 때문입니다.
압축 전략의 선택은 작업 환경에 따라 달라집니다. 쓰기 작업이 자주 일어나는 환경에서는 크기 계층 압축이 유리할 수 있습니다. 이 전략은 쓰기 증폭을 최소화하지만, 대규모 SS-Table의 병합으로 인해 읽기 성능이 저하될 수 있습니다. 반면, 쓰기가 상대적으로 적은 환경에서는 레벨 기반 압축이 더 적합할 수 있습니다. 이 방식은 읽기 성능을 향상시키지만, 더 높은 쓰기 증폭을 야기할 수 있습니다.
레퍼런스를 찾아보니 대부분의 엔진들은 읽기 성능의 중요성을 고려하여 레벨 기반 압축을 사용는 것 같고, 나머지는 궁금하시면 추가로 찾아보시면 좋을 것 같습니다.