03.Garbage Collection
24 Jul 2024Garbage Collection
GC(Garbage Collection)란?
객체에 대한 힙 저장소는 자동 저장 관리 시스템(일반적으로 가비지 컬렉터)에 의해 회수되며, 객체는 명시적으로 할당 해제되지 않습니다.
- Java Virtual Machine 명세, 섹션 3.5.3 [VMS2 1999]
가비지 컬렉션은 프로그램 실행 중에 사용되지 않는 메모리를 자동으로 회수하는 기능이다. 이를 통해 개발자는 메모리 관리의 부담을 줄이고, 메모리 누수(memory leak)를 방지할 수 있다. 그러나 가비지 컬렉션이 실행되는 동안 프로그램의 실행이 잠시 Suspend되기도 하며, 이는 CPU 사용이 민감한 프로그램의 경우 성능에 영향을 줄 수 있다.
JVM에서는 여러 Garbage Collector를 제공하기 때문에 어떤 Garbage Collector를 선택하느냐도 성능에 있어서 중요한 이슈가 된다.
GC의 대상
GC는 Heap과 Method Area에서 현재 사용되지 않는 객체인 Garbage를 모으는 작업이다. 이때 Root Set은 보통 3가지로 분류되며, 어떤 식으로든 Reference 관계가 있다면 Reachable Object(현재 사용되고 있는 객체)라고 판단한다.
- Stack의 참조 정보
- Local Variable Section, Operand Stack에 Object Reference가 있다면 Reachable Object이다.
- Method Area에 Loading된 Class, 그중에서 Constant Pool에 있는 Reference 정보
- Constant Pool을 통해 간접적으로 링크된 객체가 Reachable Object이다.
- 아직 메모리에 남아 있는 Native Method로 넘겨진 Object Reference
- JNI 형태로 현재 참조 관계가 있는 Object이기 때문에 Reachable Object이다.
이 세 가지 Reference 정보에 의해 직간접적으로 참조되고 있다면 모두 Reachable Object이고, 그렇지 않은 것은 모두 Garbage Object로 간주되어 GC의 대상이 된다.
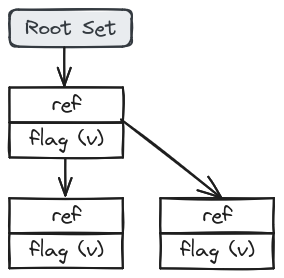
아래 그림을 보면 Root Set과 어떤 식으로든 링크가 되어 있는 것은 Reachable Object의 영역 안에 포함된다. 그리고 가장 상단에는 Root Set과 관계없이 상호 참조만 하고 있는 Object를 볼 수 있는데, Garbage Collector는 이를 Garbage로 판단한다.
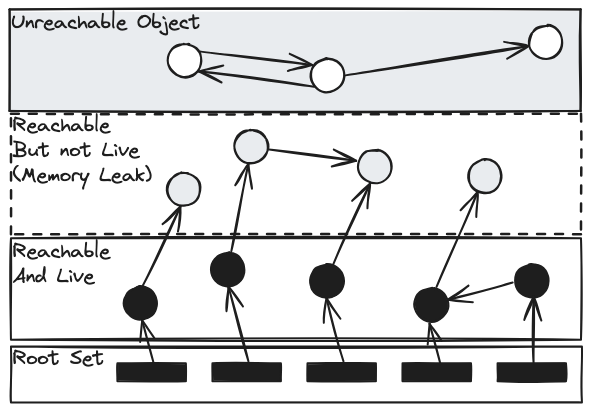
그림에서 Reachable Object But not Live는 참조는 존재하지만, 실제로는 사용되지 않는 객체를 말한다. 이는 Memory Leak이라고 볼 수 있다.
GC는 보통 메모리가 부족할 때 수행된다. 새로운 Object 할당을 위해 Heap을 재활용하기 위한 목적이라고 볼 수 있다.
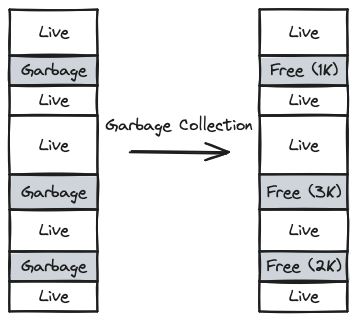
GC가 수행된 후 메모리는 듬성듬성할 수밖에 없다. 이 경우 메모리에 개별 Free Space의 크기보다 큰 Object를 할당할 경우 재활용의 의미가 사라진다.
아래 그림에서 GC가 수행되어 총 6KB의 공간이 새로 생겼다. 하지만 5KB의 Object를 할당할 수 없다. 최대 3KB만 할당 가능하다. 이 현상을 Heap의 단편화라고 하며, Garbage Collector는 Compaction과 같은 알고리즘을 사용한다.
결국 GC는 Heap을 재활용하기 위해 Root Set에서 참조되지 않는 Object를 없애는 작업이라고 할 수 있다.
GC 기본 알고리즘
이 장에서는 6가지 알고리즘을 통해 GC의 동작 원리를 이해하는 것이 핵심이다.
- Reference Counting
- Mark-and-Sweep
- Mark-and-Compacting
- Copying
- Generational
- Train
Reference Counting 알고리즘
Reference Counting 알고리즘은 Garbage Object를 찾아내는 감지(Detection)에 초점이 맞춰진 알고리즘이다. 초기 알고리즘답게 각 Object마다 Reference Count를 관리하여 Reference Count가 0이 되면 GC를 수행하도록 단순하게 구성되어 있다.
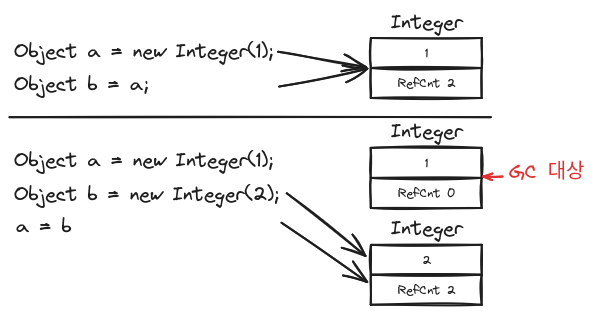
Reference Counting 알고리즘의 장점은 Pause Time이 분산되어 실시간 작업에 거의 영향을 주지 않는다는 것이다. 그러나 Reference가 변경될 때마다 각 Object의 Reference Count를 변경해야 하므로 관리 비용이 상당하다. 또한, GC가 연쇄적으로 일어날 수 있다는 문제도 있다. 순환 참조의 경우 Reference Count가 0이 될 가능성이 희박하여 메모리 누수(Memory Leak)를 유발할 가능성이 크다.
Mark-and-Sweep 알고리즘
Mark-and-Sweep 알고리즘은 Tracing 알고리즘이라고도 불리며, Reference Counting 알고리즘의 순환 참조로 인한 메모리 누수 문제와 카운팅 증감으로 인한 성능 문제를 극복하기 위해 개발되었다.
Garbage Object를 감지하기 위해 Counting 방식이 아닌 Root Set에서 시작하는 Reference 관계를 추적하는 방식을 사용한다. 이 방식은 Garbage를 찾아내는 데 상당히 효과적이기 때문에 이후의 GC에서는 대부분 이 알고리즘을 사용하고 있다.
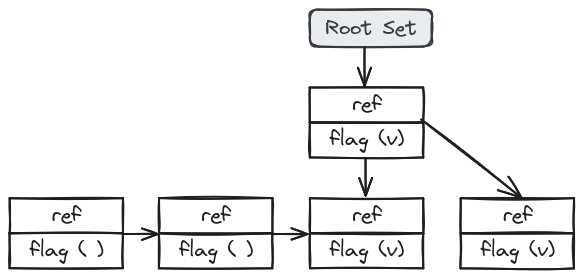
GC는 표시(Mark)와 정리(Sweep) 두 단계에 걸쳐 진행된다. Mark 단계에서는 Garbage Object를 구별하는 작업이 이루어진다. Root Set에서 Reference 관계가 있는 Object에 Marking하는 방식으로 수행되며, Object Header에 Flag나 별도의 Bitmap Table 등을 사용한다.
Mark 단계가 끝나면 즉시 Sweep 단계로 돌입한다. 이 단계는 Marking되지 않은 Object를 지우는 작업을 한다.
Mark-and-Sweep 알고리즘은 Reference 관계가 정확히 파악되고 Reference 관계 변경 시 부가적인 작업을 하지 않기 때문에 속도가 향상된다는 장점이 있다. 그러나 Mark 작업의 정확성과 메모리 손상(Memory Corruption)을 방지하기 위해 Suspend되는 현상이 발생한다. 또 하나의 문제는 메모리 단편화(Fragmentation)가 발생할 수 있다는 점이다. GC가 계속 수행되면서 공간은 있지만, 단편화가 발생하여 메모리 할당이 불가능한 상황이 되어 OOM(OutOfMemoryException)이 유발될 수 있다.
Mark-and-Compaction 알고리즘
Mark-and-Sweep 알고리즘의 메모리 단편화를 해결하기 위해 Compaction(압축) 과정이 추가되며, Sweep이 여기에 포함된다.
이 알고리즘은 Mark와 Compaction으로 구성된다. Compaction은 사용 중인 객체를 연속된 메모리 공간에 정리하여 빈 공간을 줄이고 효율성을 높인다.
Compaction에는 다음과 같은 3가지 방식이 있다
- 임의(Arbitrary) 방식: 객체들이 무작위로 이동하여 순서가 보장되지 않는다. Compaction이 임의로 진행된다.
- 선형(Linear) 방식: 객체들이 참조 순서에 따라 정렬된다. 메모리에 순서대로 배치된다.
- 슬라이딩(Sliding) 방식: 객체들이 할당된 순서에 따라 정렬된다. 빈 공간을 모으기 위해 객체를 이동시킨다.
이 중 가장 좋은 방식은 Sliding 방식으로 알려져 있다. Linear 방식은 순서를 따지는 데서 오버헤드가 발생하며, Object 탐색에는 Reference의 포인터를 기반으로 Random Access를 수행하기 때문에 인접해 있다고 큰 장점이 되지 못한다.
Compaction을 원활히 수행하기 위해 Handle과 같은 자료구조를 사용할 수도 있다.
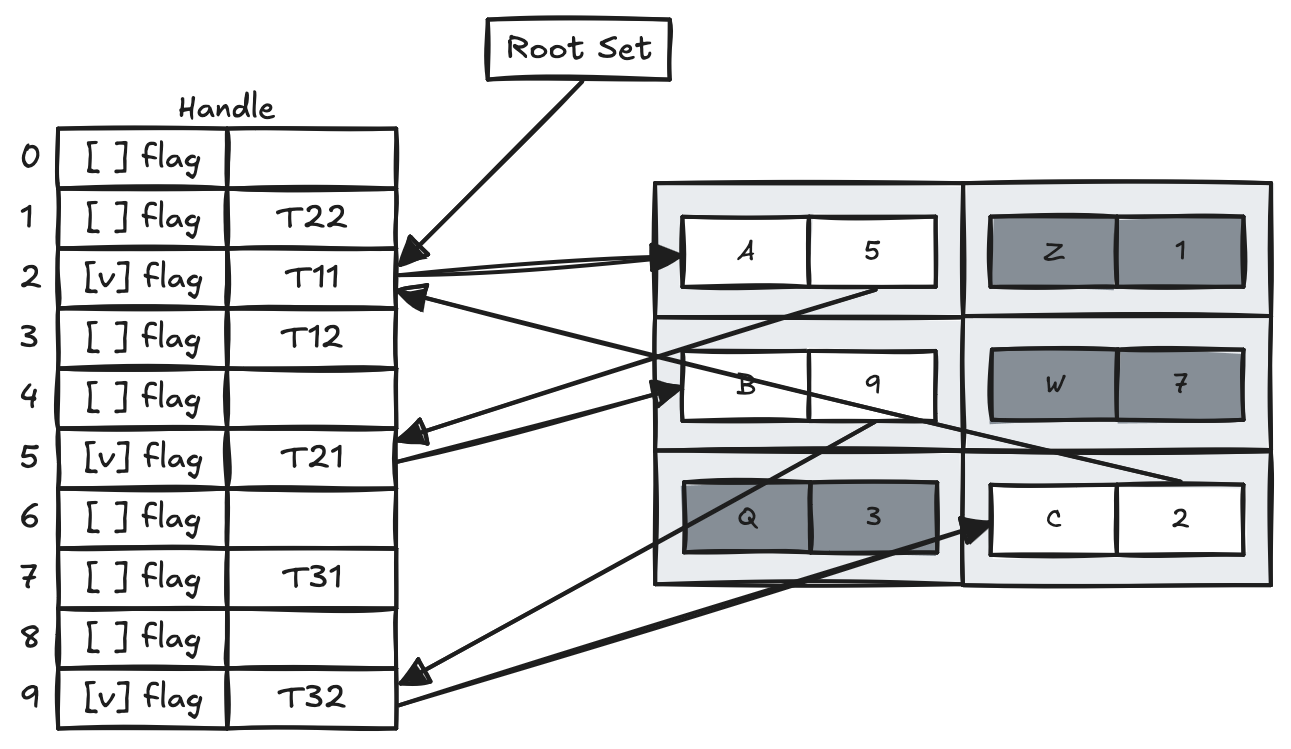
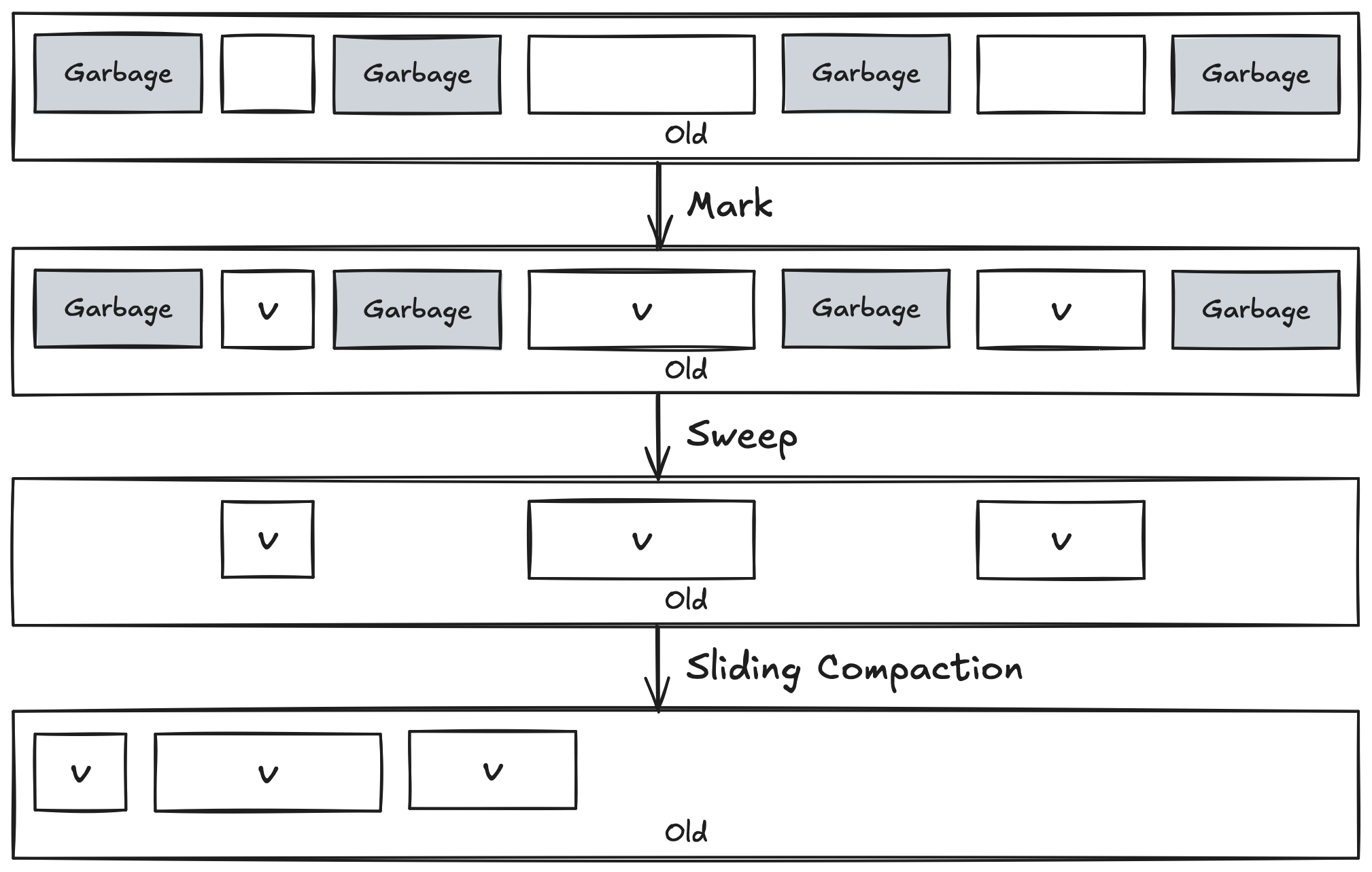
위의 그림에서는 6개의 Heap으로 구성되어 있고, Root Set과 간접적 Reference로 화살표가 이어져 있다면 Live Object로 flag에 마킹이 되어 있다. 여기서 Q, W, Z는 Garbage Object로 판단되어 flag에 마킹되지 않았다.
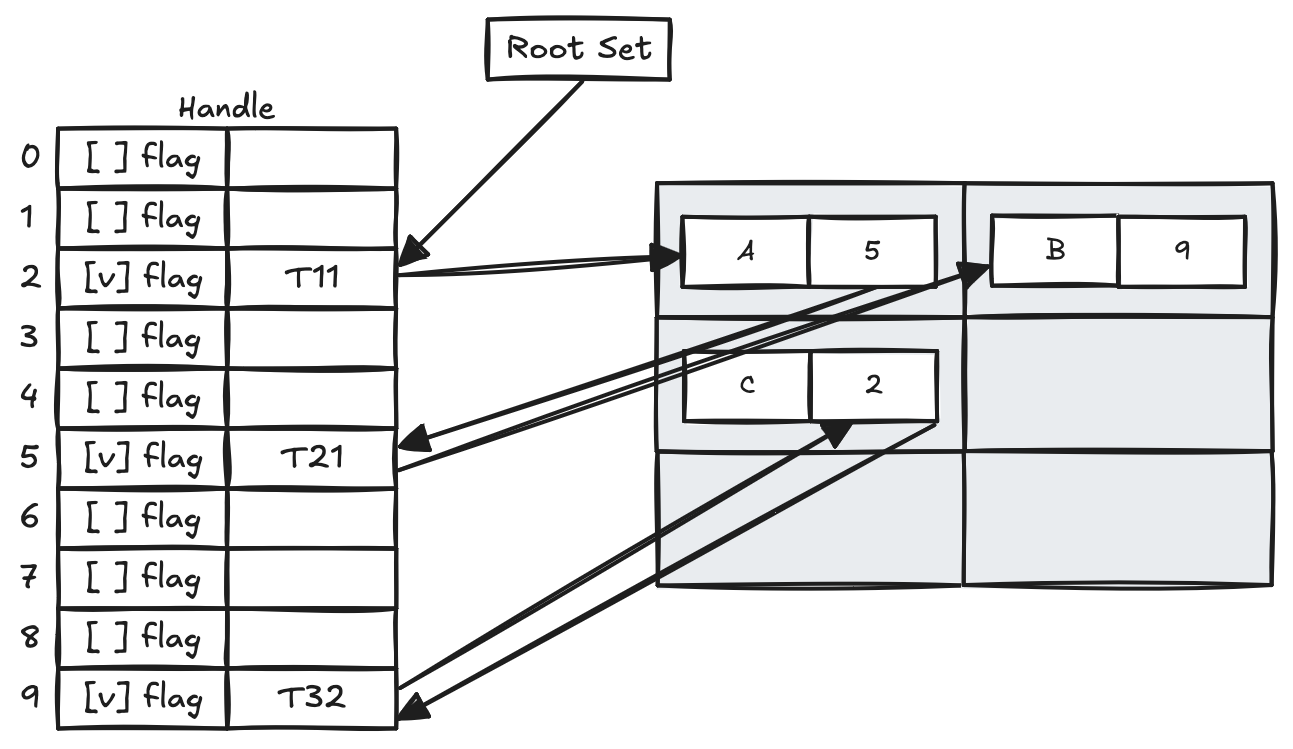
Compaction 단계에서는 Marking된 정보를 바탕으로 Garbage Object를 Sweep한 후 Heap의 한쪽 방향으로 Live Object를 이동시킨다. 이때 Sliding Compaction 방법을 사용한다.
Mark-and-Compaction 알고리즘은 단편화 방지에 초점이 맞춰져 있기에 메모리 공간 효율성이 가장 큰 장점이 된다. Compaction 이후에 모든 Reference를 업데이트하는 작업은 경우에 따라 모든 Object를 Access하는 등 부가적인 오버헤드를 수반할 수 있다. 또한 Mark 단계와 Compaction 단계는 모두 Suspend 현상이 발생한다는 단점도 있다.
Copying 알고리즘
Copying 알고리즘은 단편화 문제를 해결하기 위해 제시된 또 다른 방법이다.
Heap을 Active 영역과 Inactive 영역으로 나누어 사용하는 특징을 가진다. 이 중 Active 영역에만 Object를 할당받을 수 있고
Active 영역이 꽉 차게 되어 더 이상 Allocation이 불가능하게 되면 GC가 수행된다.
GC가 수행되면 모든 프로그램은 일단 Suspend 상태가 된다. 그리고 Live Object를 Inactive 영역으로 Copy하는 작업을 수행한다. 이 알고리즘을 Stop-the-Copying이라고도 부르는 이유이다. Object를 Copy할 때 각각의 Reference 정보도 같이 변경된다.
GC가 수행될 경우 Active 영역에는 Garbage Object만, Inactive 영역에는 Live Object만 남게 된다. 이때 Inactive 영역에 Object를 Copy할 때 한쪽 방향에서부터 차곡차곡 적재하기 때문에 마치 Compaction된 것처럼 정렬된다.
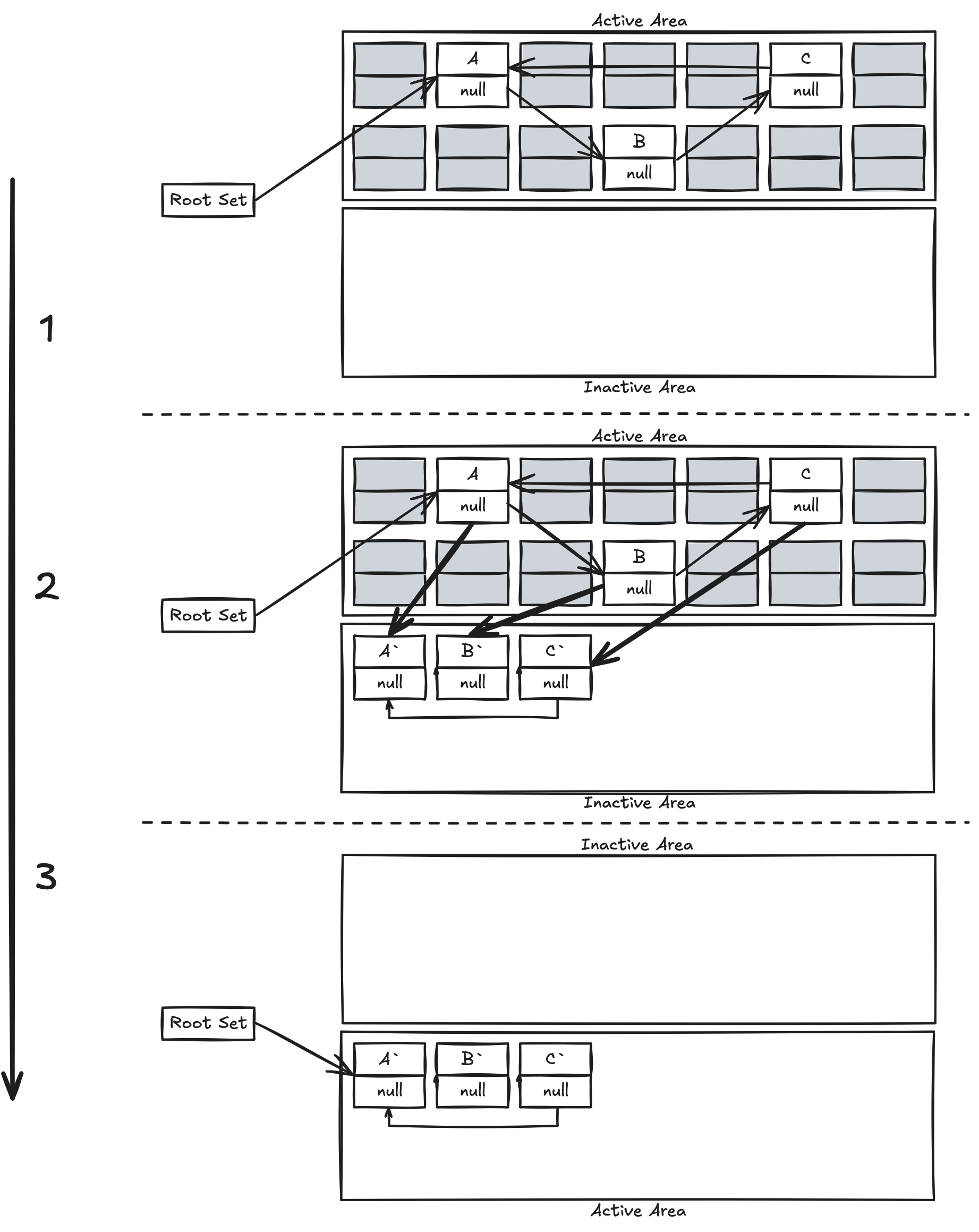
GC가 완료되는 시점에서 Active 영역은 모두 Free Memory가 되고 Active 영역과 Inactive 영역은 서로 바뀌게 된다. 이를 Scavenge라고 한다.
따라서 Active와 Inactive는 특정 메모리 번지 구간을 지칭하는 것이 아닌 현재 Allocation을 하면서 사용하는 공간이 Active, 아닌 곳이 Inactive인 논리적인 구분이다.
Copying 알고리즘은 단편화 방지에 효과적이지만 전체 Heap의 절반 정도를 사용하지 못한다는 단점이 있으며, Suspend 현상과 Copy 오버헤드는 필요악이라 할 수 있다.
Generational 알고리즘
Copying 알고리즘의 대안으로 Generational 알고리즘이 나오게 되었다. 모든 Garbage가 짧은 수명을 가진 것이 아닌 수명이 긴 몇 개의 Object는 반드시 존재하기 때문이다.
Copying 알고리즘의 연장선상으로 Heap을 Active Inactive로 나누는 것이 아니라 Age별로 몇 개의 Sub Heap으로 나눈다.
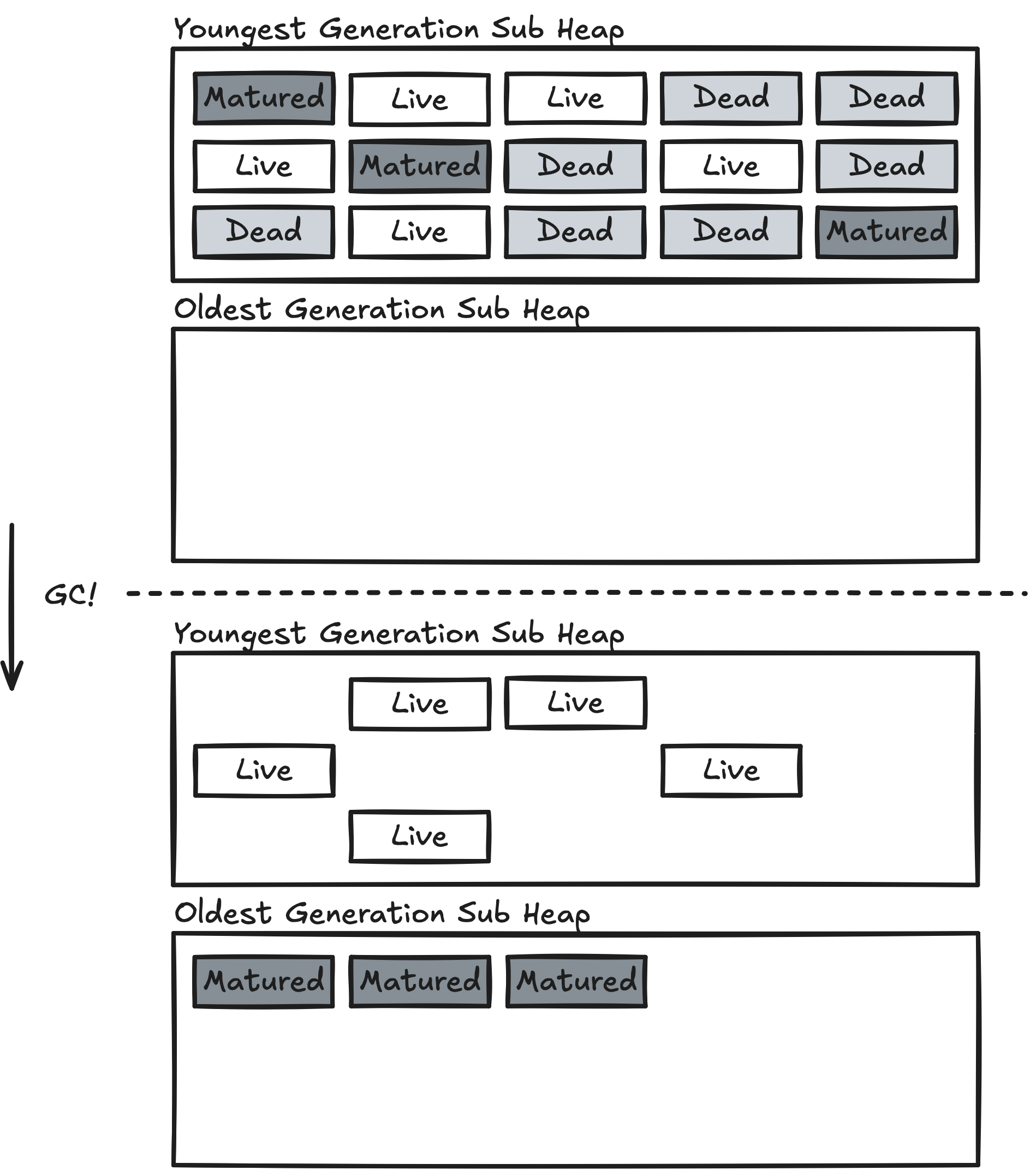
Object는 Youngest Generation Sub Heap에 할당되고, 그곳에서 성숙하게 되면 다음 Age에 해당하는 Sub Heap으로 올라가 결국 Oldest Generation Sub Heap까지 Promotion하는 방식으로 동작한다.
Age가 임계값을 넘어 다음 Generation으로 Copy되는 것을 Promotion이라고 한다.
이러한 장점으로 Hotspot JVM이나 IBM JVM에서 Generational 알고리즘을 사용하고 있다. Hotspot JVM의 경우 Generational Heap이 JVM을 대표할 정도로 GC의 기반 기술이 되어 있다.
Train 알고리즘
Tracing 알고리즘이 등장한 후 GC를 수행할 때 프로그램에 Suspend 현상이 나타나는 것은 감수할 수밖에 없었다. GC는 메모리를 재사용하기 위한 것이기 때문에 목적에 충실했었을 것이라 추측된다.
하지만 전반적인 성능에서 GC 시 발생하는 Suspend은 좋지 않다. WAS처럼 짧은 트랜잭션을 처리하는 시스템에서 Suspend 현상은 사용자에게 불쾌감을 주어 비즈니스에 악영향을 끼친다.
Train 알고리즘은 이러한 배경에서 등장한 것으로 보인다. Train 알고리즘은 Heap을 작은 Memory Block으로 나누어 Single Block 단위로 Mark 단계와 Copy 단계로 구성된 GC를 수행한다. 이러한 특징 때문에 Incremental 알고리즘이라고도 한다.
GC 단위가 Single Block인 만큼 전체 Heap의 Suspend가 아닌 GC 중인 Memory Block만 Suspend가 발생한다. 다시 말해 Suspend를 분산시켜 전체적인 Pause Time을 줄이자는 아이디어이다.
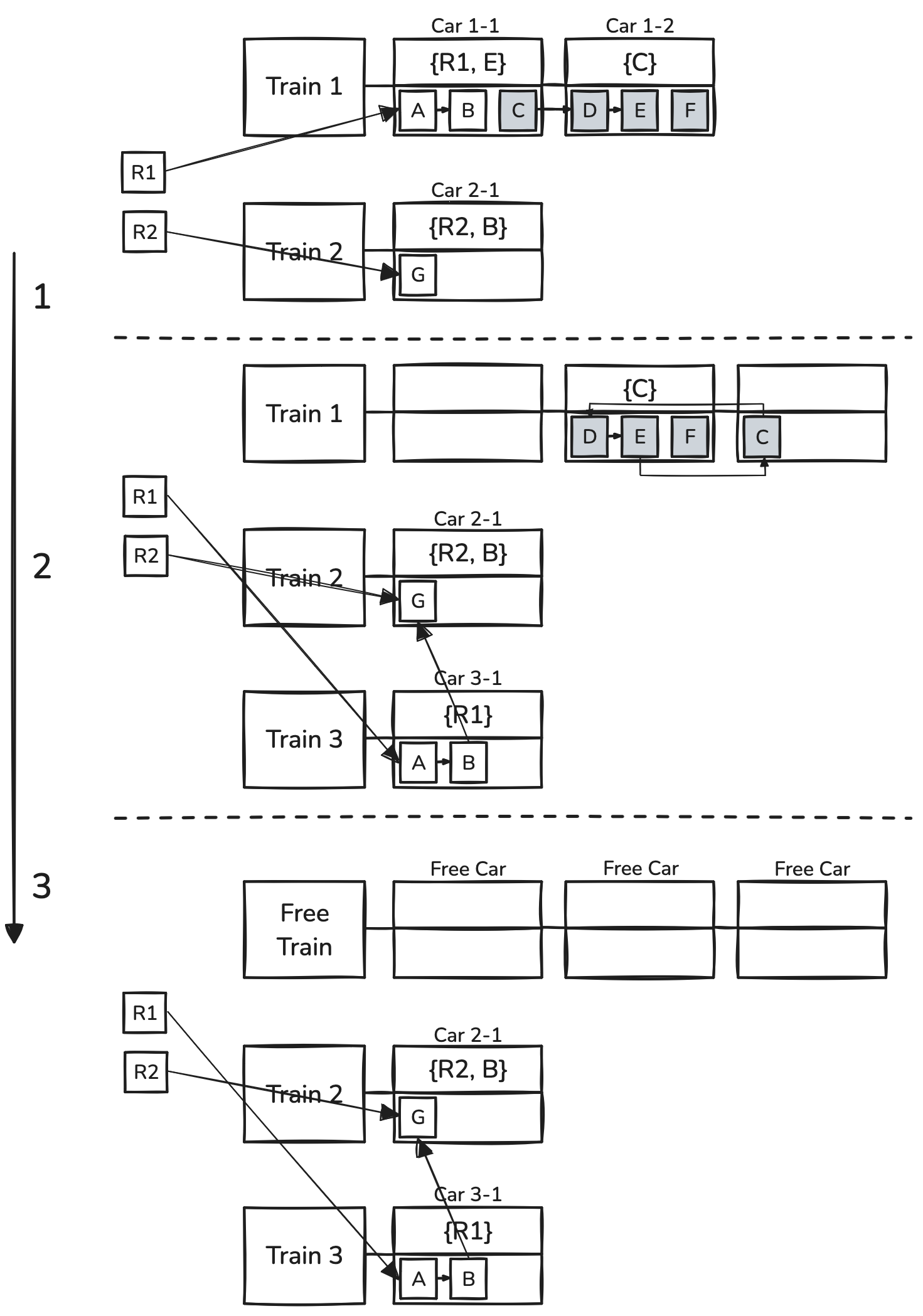
Train 알고리즘은 Heap을 Train으로 구성한다. Train은 고정 크기의 메모리 블록인 Car로 이루어져 있다. 필요에 따라 Train에 Car를 추가하거나, Train 자체를 추가할 수 있다.
각 메모리 블록에는 Car 외부에서 참조하는 객체들을 기억하는 Remember Set이 있다. GC 동안 객체의 주소가 변경될 때, 모든 참조를 탐색하는 오버헤드를 줄이기 위해 Reference를 기록해 놓는다. 이렇게 하면 GC 과정에서 주소가 변경되어도 참조하는 객체의 주소를 업데이트할 수 있다.
Remember Set을 구성하기 위해 Write Barrier라는 장치가 있다. 이는 간단한 코드로 이루어져 있으며, 이벤트 트리거로 작동한다. GC 과정에서 주소가 변경될 때 트리거되어 Remember Set을 통해 참조 객체의 주소를 변경해준다.
Adaptive 알고리즘
Adaptive 알고리즘은 특정 Collection 방법을 지칭하는 것이 아니라, Heap의 현재 상황을 모니터링하여 적절한 알고리즘을 선택 적용하는 것 또는 Heap Sizing을 자동화하는 일련의 방법을 말한다.
Adaptive 알고리즘은 Hotspot JVM의 Ergonomics 기능 또는 Adaptive Option이나 IBM JVM의 Tilting 기능 등으로 구현되고 있다.
Hotspot JVM의 GC
Hotspot JVM의 중요한 특징 중 하나는 Heap을 Generation으로 나누어 사용하는 것이다. Heap은 Young Generation과 Old Generation으로 나뉜다.
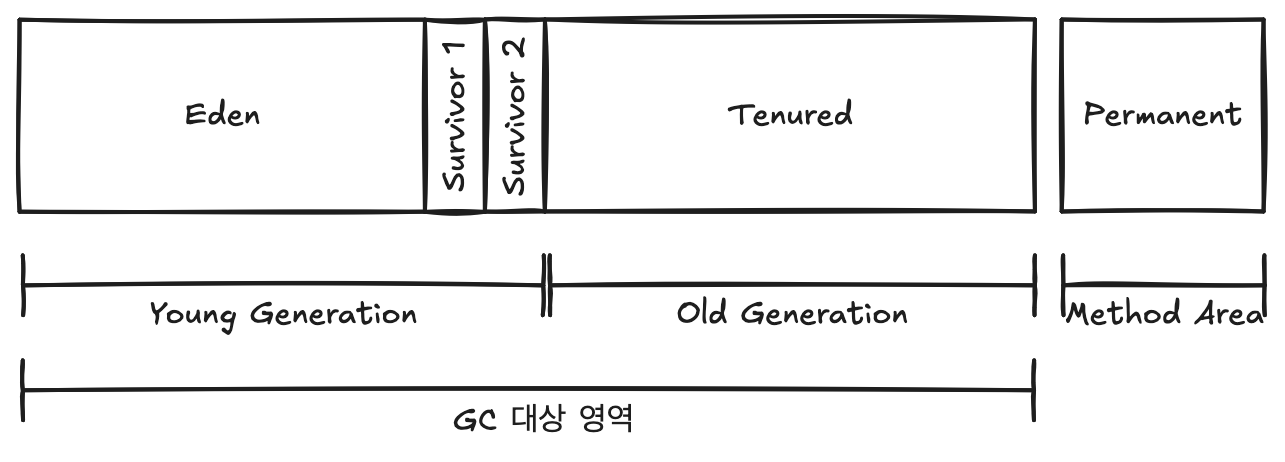
Young Generation
Young Generation은 객체가 처음으로 할당되는 영역이다. 이 영역은 다시 Eden 영역과 두 개의 Survivor 영역으로 나뉜다. 객체는 처음에 Eden 영역에 할당되고, 여기서 살아남은 객체는 Survivor 영역으로 복사된다. Survivor 영역은 To와 From 영역으로 불리며, Old Generation으로 이동하기 전에 객체가 머무는 장소이다.
Old Generation
Old Generation은 Young Generation에서 성숙한 객체가 Promotion되어 이동하는 영역이다. 큰 객체는 Young Generation을 거치지 않고 바로 Old Generation에 할당될 수 있다.
Weak Generational Hypothesis
Heap을 Generation으로 나누어 구성하는 것은 Weak Generational Hypothesis에 기반한다. 이 가설은 대부분의 객체가 새로 생성된 후 얼마 지나지 않아 Garbage가 된다는 내용을 포함한다. Young Generation에서 GC가 빈번하게 발생하는 이유는 이 때문이다. Eden 영역은 할당 전용 공간으로 사용되고, GC 당시 살아남은 객체는 Survivor 영역으로 옮겨진다. 오래 지속되는 객체를 위한 Old Generation 영역이 별도로 구분되어 있다.
Minor GC와 Major GC
Young Generation에 메모리 압박이 생기면 Minor GC가 발생한다. Minor GC의 결과로 충분히 성숙된 객체는 Old Generation으로 Promotion된다. Old Generation의 메모리가 부족할 경우 Major GC가 발생한다. Major GC는 Promotion 과정에서 메모리가 부족해서 발생하기 때문에 Minor GC와 분리해서 생각할 수 없다. 또한, 너무 많은 수의 Class Object가 로딩되어 Permanent Area가 부족할 경우에도 Full GC가 발생할 수 있다.
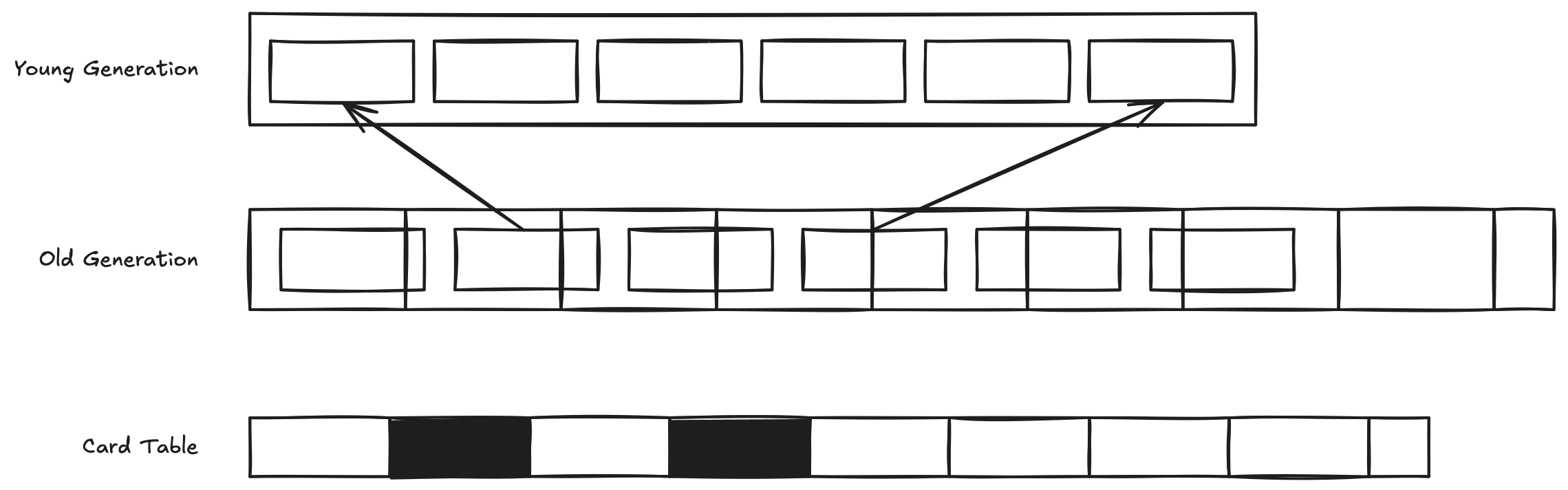
GC의 효율성 유지
Older Object가 Young Object를 참조하는 일은 드물다. 이는 Minor GC가 가볍게 유지되기 위한 중요한 요소다. Hotspot JVM은 Older Object가 Young Object를 참조하는 경우를 대비하여 Card Table과 Write Barrier를 사용한다. Write Barrier는 Old Object가 Young Object를 참조하면 Card에 Dirty 표시를 하고, 참조가 없어지면 Dirty 표시를 지운다.
JVM 옵션
Hotspot JVM의 GC 설정은 서버와 클라이언트 애플리케이션에 맞춰 자동으로 조정된다. 서버는 Parallel Collector와 Server Compiler를, 클라이언트는 Serial Collector와 Client Compiler를 사용하며, 설정은 옵션으로 변경할 수 있다. Heap Sizing 관련 JVM 옵션으로는 다음과 같은 것들이 있다.
Java 21 기준
-server와-client: 각각 Server와 Client Hotspot VM으로 구동됨- 참고: 자바 9 이후로
-client옵션은 더 이상 사용되지 않으며, 대부분의 경우-server옵션이 기본 설정으로 적용됨
- 참고: 자바 9 이후로
-Xms<size>: Heap의 초기 크기를 지정함-Xmx<size>: 확장 가능한 Heap의 최대 크기를 지정함-XX:NewRatio=<value>: Young/Old Generation 크기의 비율을 나타냄-XX:SurvivorRatio=<value>: Eden/Survivor 공간의 비율을 지정함-XX:MetaspaceSize=<size>: Metaspace의 초기 크기를 지정함-XX:MaxMetaspaceSize=<size>: Metaspace의 최대 크기를 지정함- 참고: 자바 8 이후로 Permanent Area가 Metaspace로 대체됨
-XX:InitialRAMPercentage=<value>: 초기 Heap 크기를 가용 RAM의 비율로 지정함-XX:MaxRAMPercentage=<value>: 최대 Heap 크기를 가용 RAM의 비율로 지정함-XX:MinRAMPercentage=<value>: 최소 Heap 크기를 가용 RAM의 비율로 지정함
자바 7 이전 기준 (책 원본)
-server와-client: 각각 Server와 Client Hotspot VM으로 구동된다.-Xms<size>: Heap의 초기 크기를 지정한다.-Xmx<size>: 확장 가능한 Heap의 최대 크기를 지정한다.-Xmn<size>: Young Generation의 크기를 지정한다.-XX:NewRatio=<value>: Young/Old Generation 크기의 비율을 나타낸다.-XX:SurvivorRatio=<value>: Eden/Survivor 공간의 비율을 지정한다.-XX:PermSize=<size>: Permanent Area의 초기 크기를 지정한다.-XX:MaxPermSize=<size>: Permanent Area의 최대 크기를 지정한다.
Hotspot JVM은 각 Generation별로 GC를 수행하며, 각각의 Generation에 대해 다른 Garbage Collector를 지정할 수 있다. Young Generation에 메모리 압박이 생기면 Minor GC가 발생하고, Old Generation에 메모리 압박이 생기면 Major GC가 발생한다. 이러한 설정과 조정은 JVM 옵션을 통해 세밀하게 조절할 수 있다.
Garbage Collector
Hotspot JVM은 버전을 거듭하면서 Garbage Collector(GC)를 추가하는 방식으로 GC를 개선해왔다. Hotspot JVM에서 적절한 Garbage Collector를 선택하는 것은 GC 최적화의 핵심이다.
Java 21 기준
| Garbage Collector | Young Generation Collection Algorithm | Old Generation Collection Algorithm | Option |
|---|---|---|---|
| Serial Collector | Generational | Mark-and-Compact | -XX:+UseSerialGC |
| Parallel Collector | Parallel Copy | Mark-and-Compact | -XX:+UseParallelGC |
| G1 Collector (Default Collector) | Generational | Mixed | -XX:+UseG1GC |
| ZGC | Concurrent | Concurrent | -XX:+UseZGC |
| Shenandoah | Concurrent | Concurrent | -XX:+UseShenandoahGC |
| Epsilon | N/A | N/A | -XX:+UseEpsilonGC |
| CMS Collector | Parallel Copy | Concurrent | Deprecated in Java 14 |
자바 7 이전 기준 (책 원본)
| Garbage Collector | Young Generation Collection Algorithm | Old Generation Collection Algorithm | Option |
|---|---|---|---|
| Serial Collector (Default Collector) | Generational | Mark-and-Compacting | -XX:+UseSerialGC |
| Parallel Collector | Parallel Copy | Mark-and-Compacting | -XX:+UseParallelGC |
| Parallel Compacting Collector | Parallel Copy | Parallel Compacting | -XX:+UseParallelOldGC |
| CMS Collector | Parallel Copy | Concurrent | -XX:+UseConcMarkSweepGC |
| Incremental Collector | Generational | Train | -Xincgc |
다시 책 내용 기준
Serial Collector
Serial Collector는 Young & Old Generation에서 GC를 Single CPU(1 Thread)를 통해 처리한다.
Young Generation : Generational 알고리즘
Young Generation의 GC 알고리즘은 Generational 알고리즘을 사용한다.
Mark 단계가 끝나고, Live Object가 식별되었다. 이를 통해 Survivor2로 Live Object들을 모두 Copy하고, Sweep을 통해 이외의 영역을 모두 청소(Scavenge)한다. 이를 Minor GC라고 한다. 청소가 끝나면 JVM은 정지를 풀고 다시 Application 실행을 재개한다.
Survivor1,2에 From, To가 붙어있지만 논리적인 구분이다.
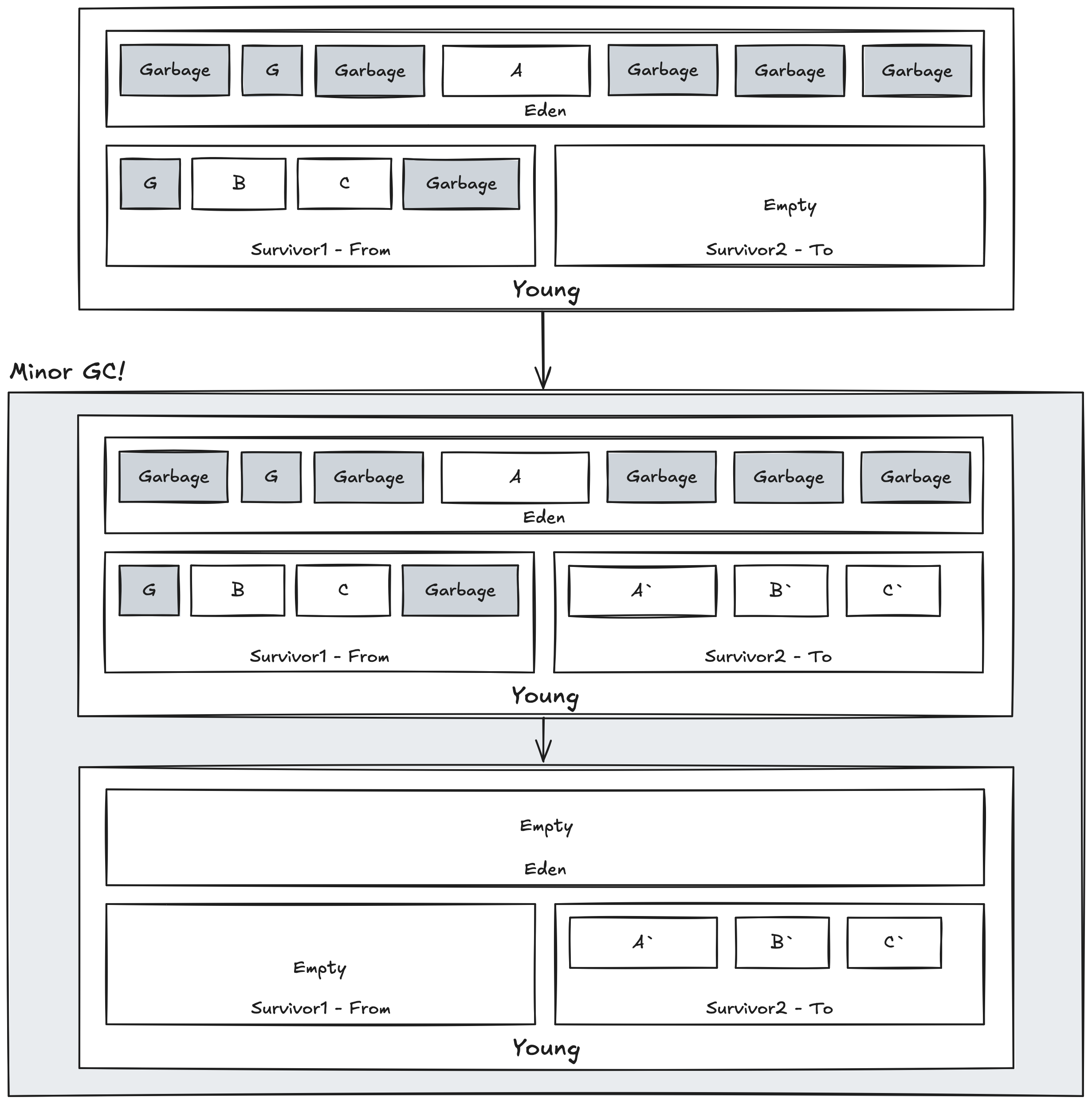
MinorGC 도중 Promotion되는 과정
Promotion은 Young Generation에서 성숙된(Matured)된 Object가 Old Generation으로 복제됨을 의미한다. Generational Algorithm은 각 Object마다 Age를 기록하여 성숙도를 판단한다.
Object의 Age는 MinorGC 때 Garbage되지 않고 Survivor Area로 이동한 횟수를 의미하며 Hotspot JVM은 Object Header에 기록한다.
Hotspot JVM은 Age와 함께 Promotion을 위한 -XX:MaxTenuringThreshold 같은 임계값 옵션을 제공해주고 있다.
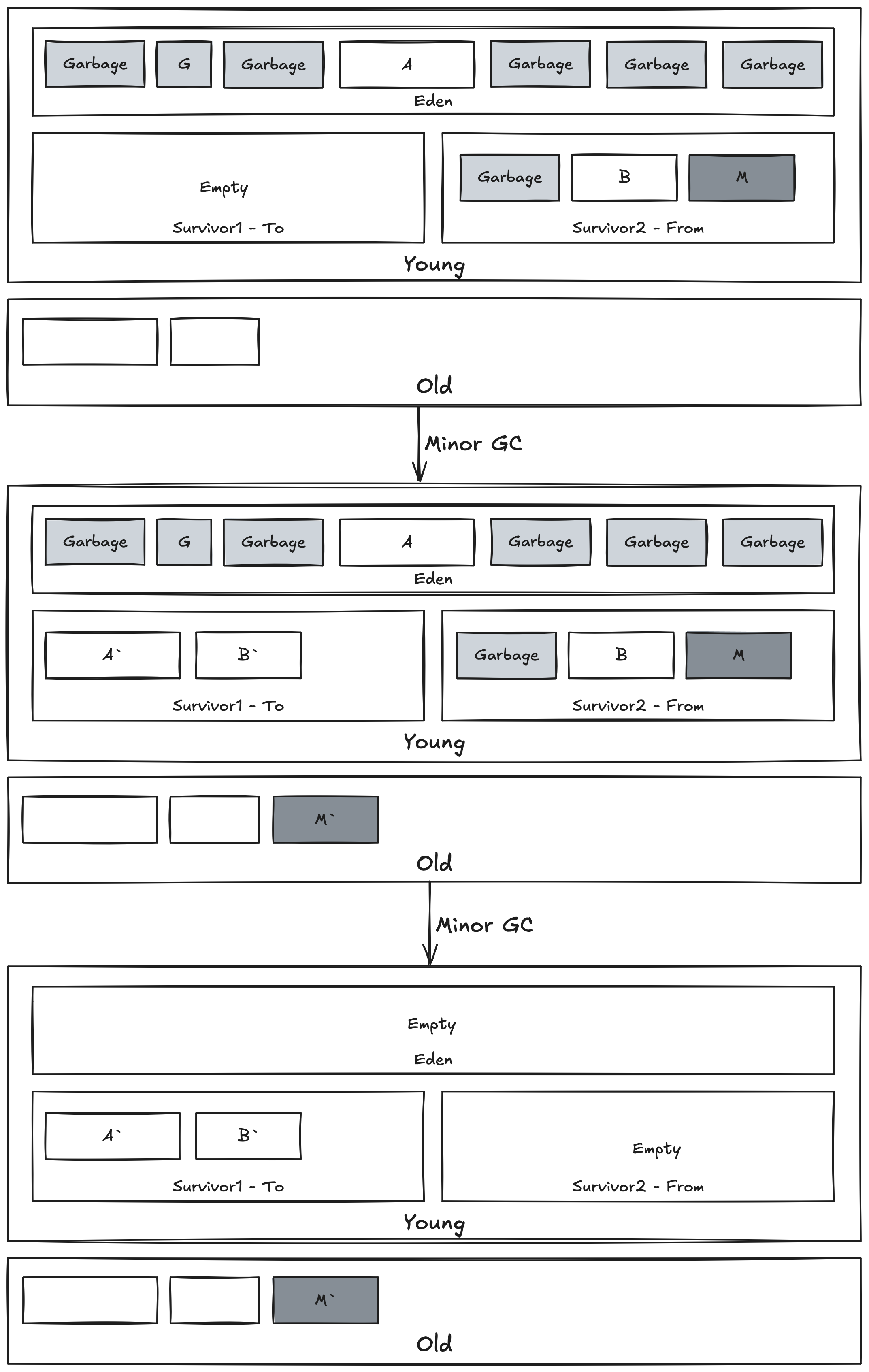
Old Generation : Mark-and-Compacting 알고리즘
Old Generation은 Young Generation과 다른 방식으로 GC를 수행한다. Old Generation의 크기가 Young Generation보다 크고 수행 방식에 차이가 있기 때문에 Minor GC보다 Suspend Time이 길다. 이때 Garbage를 정리(Sweep), 정렬(Compaction) 과정에서 시간을 많이 소요한다.
게다가 Minor GC 와중에 Promotion을 위한 Old Generation에서의 공간이 부족하게 되면 Full GC가 이어서 일어나기 때문이다.
Incremental Collector
Incremental Collector는 Low Pause Goal을 가진 최초의 Collector이다. Low Pause 전략은 GC로 인한 Suspend 자체를 분산시키는 것이 핵심이다.
Young Generation에서 Serial Collector와 동일한 Generational 알고리즘을, Old Generation에서는 Train 알고리즘을 사용한다.
Old Generation : Train 알고리즘
Old Generation을 64KB 단위의 Fixed Size Memory Block으로 나누고 Block을 대상으로 GC를 수행한다.
Single Block 단위로 GC를 수행하기 때문에 Suspend Time이 분산되어 Low Pause가 된다.
Minor GC가 발생할 때마다 Major GC가 발생하고 1개 Memory Block을 GC하게 된다. Train 알고리즘은 Copy 작업을 전제로 하기 때문에 메모리가 부족하면 OOM이 발생할 수 있다. 이때는 Mark-and-Compaction 알고리즘으로 선회하여 GC를 재개한다.
Incremental Collector는 Java 6에서 공식적으로 사라지게 되었다. 메모리 단편화의 위험성 때문에 Memory Block을 가득 차게 쓰기 힘들기 때문에 Old Generation이 클수록 Memory Block의 단편화 현상은 심화된다.
또한 Minor GC마다 Major GC를 수행하는 것은 Overhead로 작용한다. 약 10% 이상의 공간을 Remember Set으로 사용하기 때문에 메모리가 낭비된다.
Parallel Collector
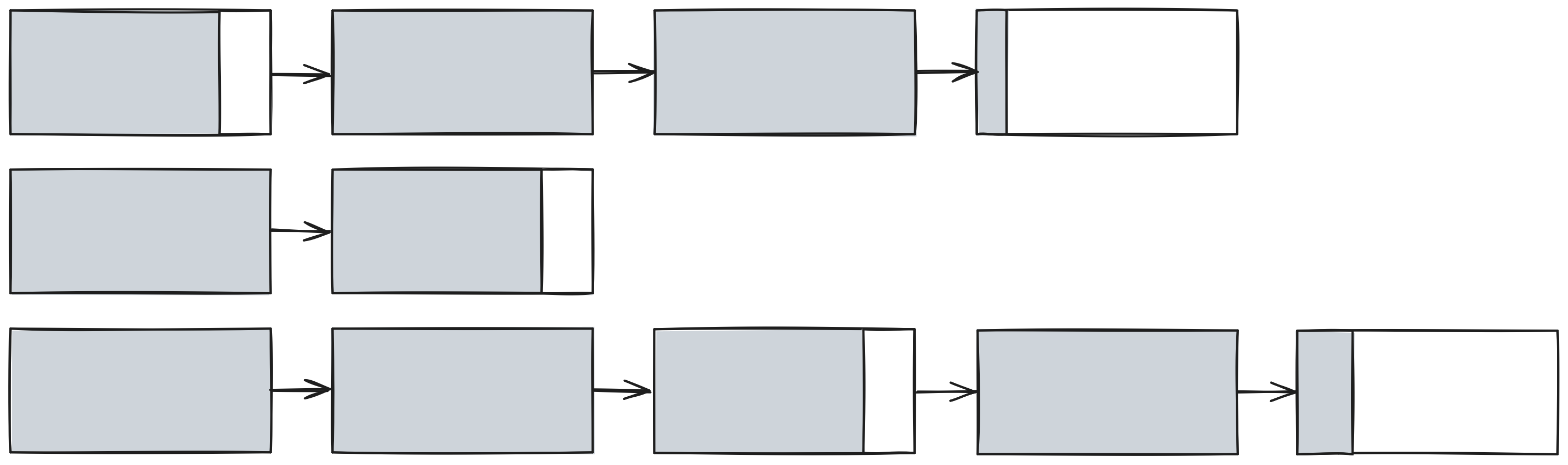
Parallel Collector는 Serial Collector의 1개 Thread로 GC를 수행하던 것과 달리 Multi-Thread가 동시에 GC를 수행하여 Throughput Goal에 적합하다.
Parallel Collector의 적용 범위는 Young Generation에 국한되며 Old Generation에서는 Serial Collector와 동일한 Mark-and-Compacting 방식을 유지하고 있다.
Young Generation : Parallel Copy 알고리즘
Parallel Copy 알고리즘은 Generational 알고리즘과는 Multi Thread로 동시에 처리한다는 차이만 존재한다.
Copy 작업에서 Suspend 현상이 발생하는 건 동일하지만 리소스를 더 투입하는 만큼 시간이 단축된다.
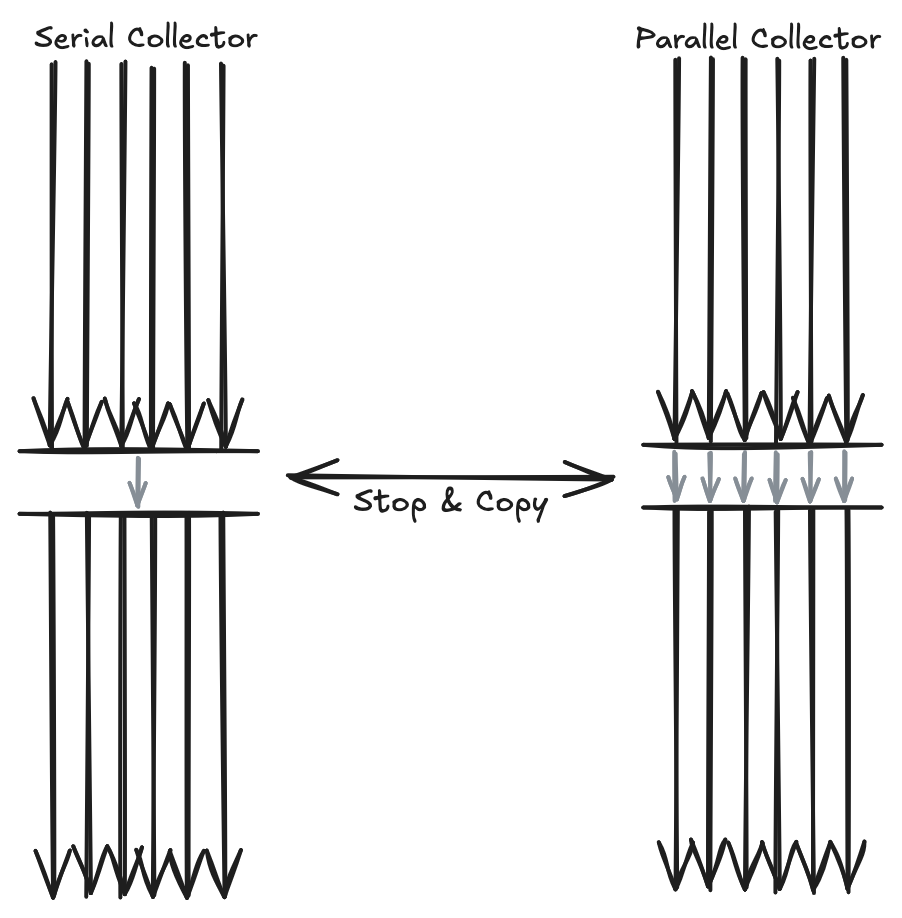
Generational 알고리즘의 Copy 작업은 다른 메모리 영역으로 쓰는 작업으로 구성되어 있기 때문에 GC Thread가 여러 개로 늘었다는 건 산술적인 증가 이상의 의미가 있다.
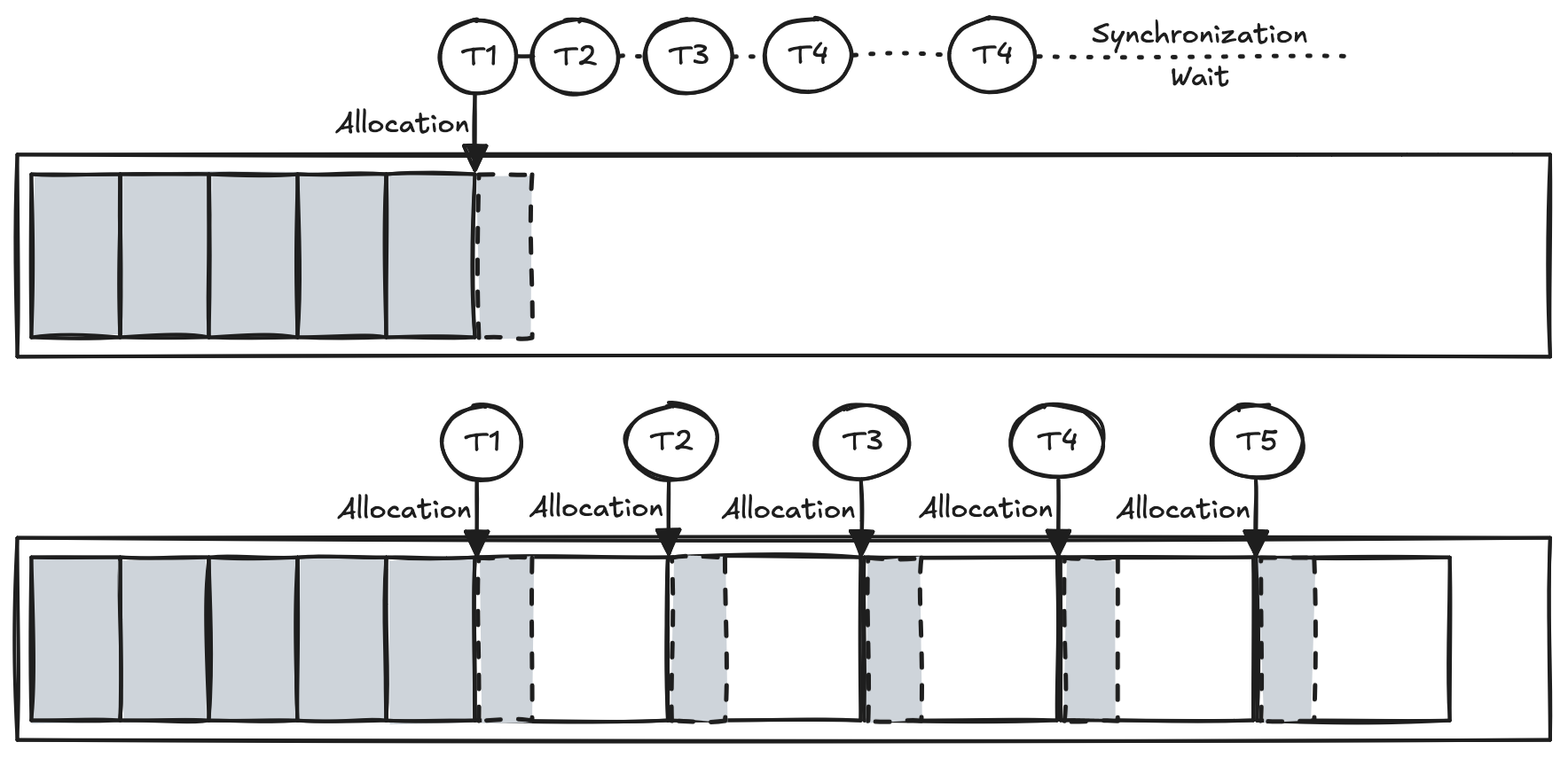
메모리 특성상 같은 메모리 공간을 두 Thread 혹은 Process가 접근하게 되면 Corruption이 발생할 수 있기 때문에 Memory Corruption 위험 정도 측면에서 비교가 되지 않는다. 이러한 Corruption을 회피하기 위해 동기화 작업이 수반되어야 하는데 이 경우 Promotion 성능이 떨어지게 된다.
그래서 Hotspot은 PLAB(Parallel Local Allocation Buffer)이라는 이름의 Promotion Buffer를 마련했다. 이는 GC Thread가 Promotion 시에 배타적으로 사용하기 위해 Thread마다 Old Generation의 일정 부분을 할당해 놓은 것이다. 보통 1024 Bytes 단위로 할당받으며 이를 모두 사용하면 다시 Buffer를 재할당받는다.
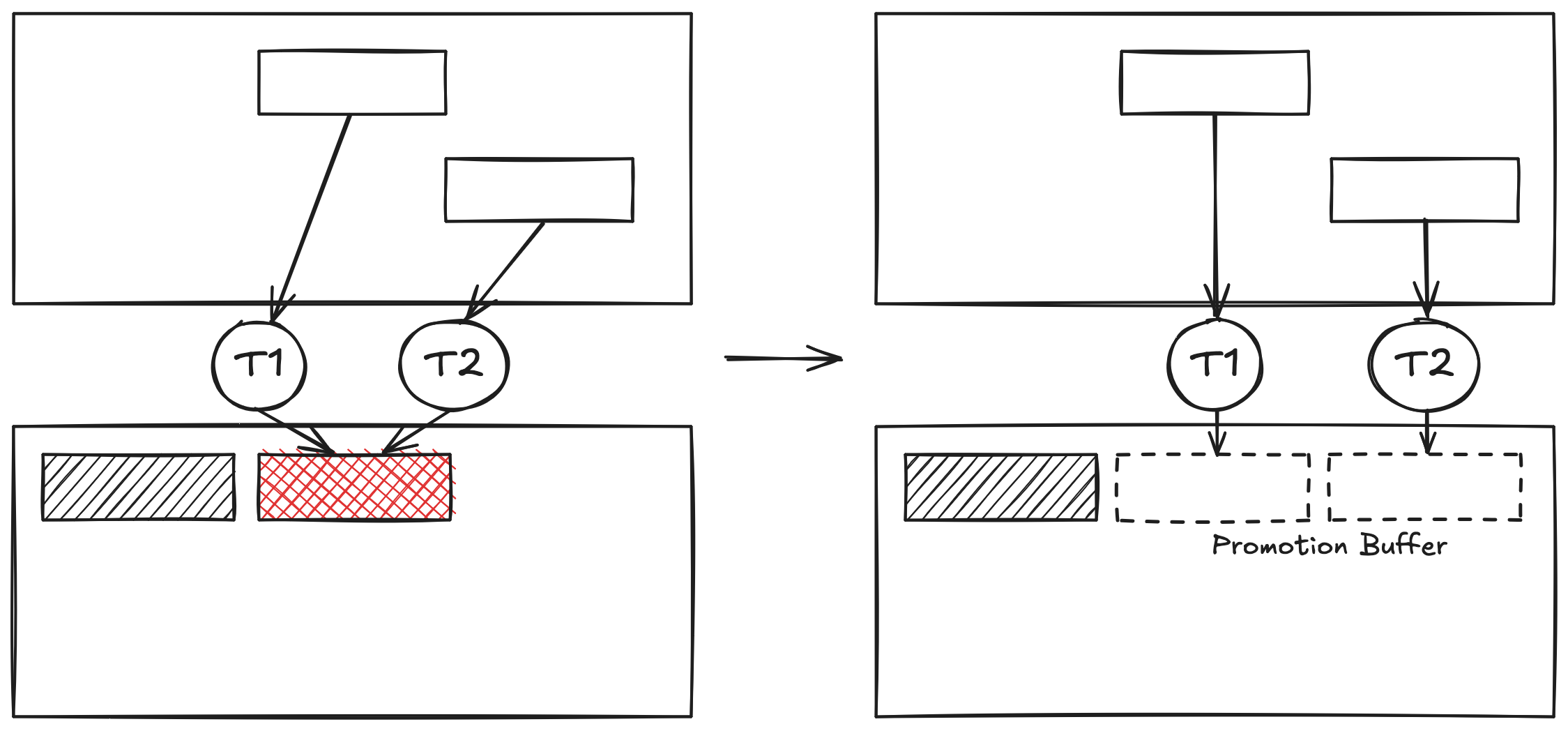
이때 Promotion Buffer는 동기화 발생 회피를 하게 해주지만 Old Generation에 단편화 문제가 발생할 수 있다. 많은
수의 Thread가 Buffer를 할당받고 사용하지 않거나 어쩔 수 없이 발생하는 Buffer 자투리 공간이 Heap 단편화 원인이 될 수 있다.
이렇게 단편화 문제가 발생할 경우 GC Thread 수를 감소시키거나 Old Generation의 Size를 늘리는 방법으로 문제를 회피할 수 있다.
CMS(Concurrent Mark-Sweep) Collector
CMS Collector는 Pause Time Goal에 맞는 Collector이다.
CMS Collector는 Fast Elapsed Time에 중점을 두고 있어 Low Latency Collector라고도 불린다. GC에서 수반되는 Suspend Time을 적절히 분산하여 응답 시간을 개선하는 방식을 사용한다.
Young Generation에서는 Parallel Collector와 동일한 Parallel Copy 알고리즘을 사용하고, Old Generation에서는 CMS 알고리즘을 사용하고 있다.
Old Generation : CMS 알고리즘
CMS 알고리즘은 4단계로 구성되어 있다.
- Initial Mark 단계는 Serial 단계이며 Suspend 상태가 된다. 그러나 Root Set에서 직접 Reference(1 Depth)되는 Object만을 대상으로 하기 때문에 Suspend Time은 최소화된다.
- Concurrent Mark 단계도 Serial 단계이며 Initial Mark 단계에서 선별된 Live Object를 대상으로 Reference하고 있는 Object를 추적하여 Live 여부를 구별한다.
- Concurrent가 이름에 들어가는 이유는 다른 JVM 내 Working Thread들은 그대로 동작한다. (즉 Suspend되지 않음)
- Remark 단계는 Parallel 단계로 모든 Thread가 GC에 동원된다. 그렇기 때문에 Suspend Time이 발생하며 이미 Marking된 Object를 다시 추적하여 Live 여부를 확정하게 된다. Remark 단계가 가장 작업량이 많기 때문에 가용한 모든 리소스를 투입하는 것이다.
- Concurrent Sweep 단계도 Serial 단계이며 Application과 GC가 동시 작업이 가능하다. Remark 단계에서 최종 Live로 판명된 Object를 제외한 Garbage Object를 지워 공간을 재활용 가능하도록 한다. 하지만 Compaction은 수행하지 않는다.
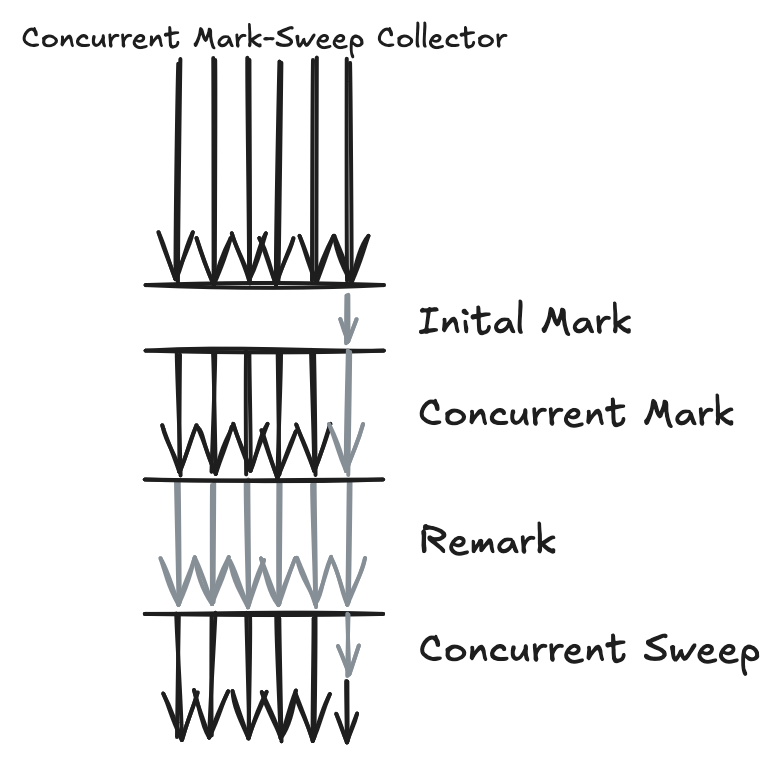
Compaction을 수행하기 위해서는 Heap의 Suspend가 전제되어야 한다. 그러나 CMS Collector는 Compaction을 포기하고 최대한 Application의 수행을 보장한다.
반복된 Sweep을 통해 Free Space가 감소하면 Heap의 단편화가 유발될 수 있다. 이를 방지하기 위해 다음과 같은 방법을 사용한다:
- 프리 리스트 사용: Young Generation에서 승격된 객체와 크기가 비슷한 Free Space를 탐색한다.
- 승격 객체 크기 통계: 승격되는 객체의 크기를 지속적으로 통계화하여 미래의 요구량을 추정한다.
- 메모리 블록 관리: 추정된 양에 따라 Sweep의 결과로 얻어진 Free Memory 블록들을 적절히 붙이거나 쪼개어 가장 적절한 크기의 Free Memory Chunk에 객체를 할당한다.
이러한 방법은 Fragmentation 가능성을 줄일 수 있지만, Compaction 방식을 사용하는 것에 비해 Garbage Collection 중 Young Generation의 부담을 증가시킬 수 있다. Compaction 작업에서는 승격된 객체들이 순서대로 할당받기만 하면 되므로 빠른 할당이 가능하지만, 프리 리스트를 사용하면 가장 적합한 크기를 찾기 위해 프리 리스트를 탐색해야 하므로 Old Generation의 할당에 시간이 많이 걸린다.
결국, 승격된 객체들이 Eden 영역 또는 Survivor 영역에서 체류하는 시간이 길어질 수 있다. 그러나 Compaction 작업 자체가 고비용이기 때문에 전체적인 손익을 고려할 때, 특히 승격이 빈번하지 않은 경우 성능상의 이득이 더 클 수 있다.
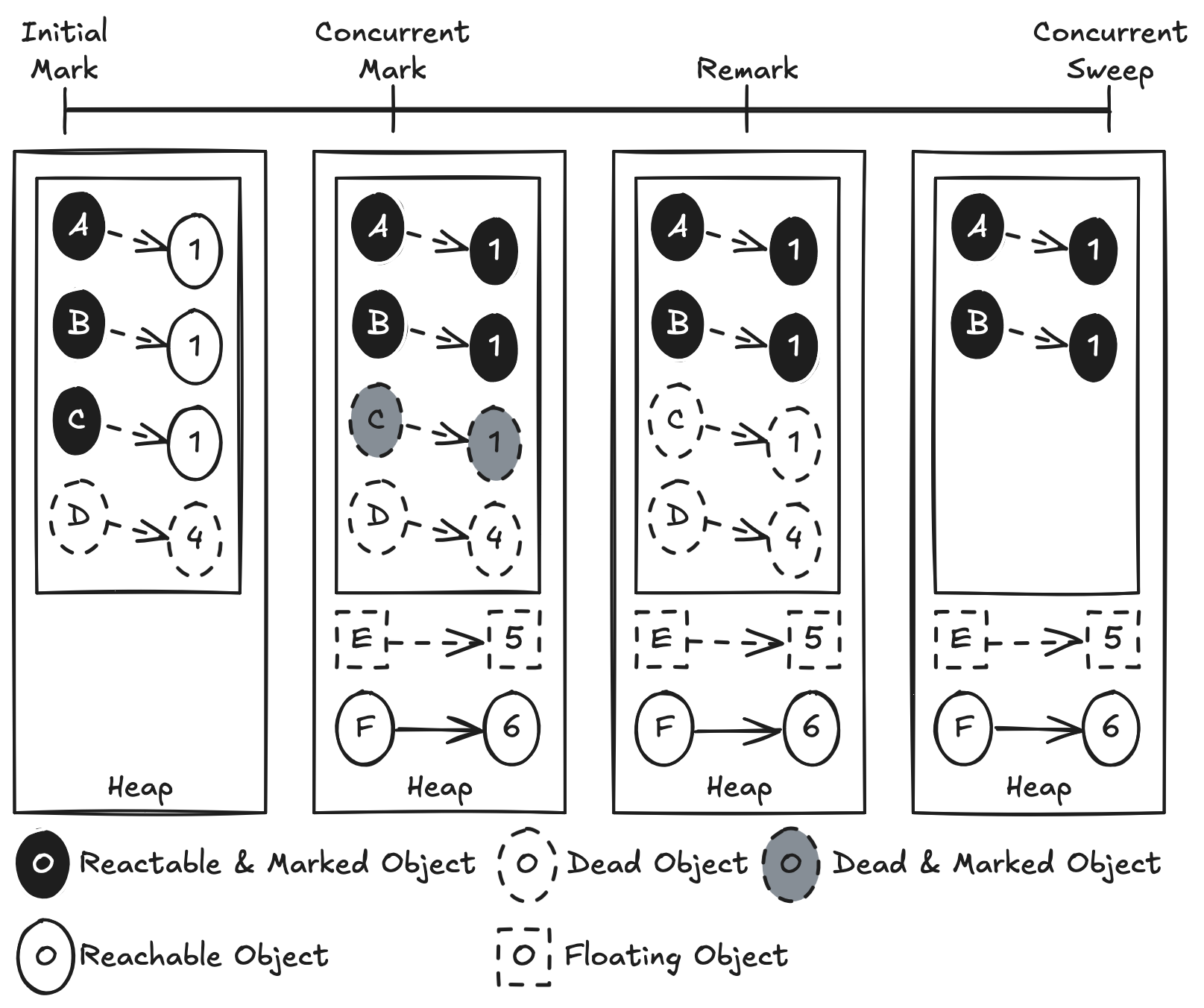
추가로 Floating Garbage 문제를 일으킬 수 있다. Floating Garbage는 수거되지 않고 남아 있는 Garbage를 의미한다.
- Initial Mark 단계에서 객체 A, B, C가 Reachable로 판별되었고, 객체 D는 Dead Object로 식별된다.
- Concurrent Mark 단계에서 Application은 그대로 동작 중이기 때문에 A, B, C가 참조하는 객체 1, 2, 3이 Dead Object로 변할 수 있다.
- 새로운 객체 E, F, 5, 6이 Promotion되어 Old Generation에 추가되지만, CMS Collector는 Initial Mark 단계에서 Live로 인정된 객체만을 대상으로 하므로 이들은 GC에서 제외된다.
- Floating Garbage는 다음 GC에서 사라지게 된다.
CMS Collector는 Major GC에서 Pause Time을 최대한 감소시키는 방식으로 동작하지만 Suspend Time을 완벽히 없애지는 못했다. 그리고 Minor GC와 Major GC에서 Remark가 연달아 수행된다면 Pause Time Goal에서 의도한 Suspend Time보다 길어질 것이다.
이를 위해 Schedule을 고려하며 두 가지 목적이 존재한다.
- Minor GC와 Remark 단계가 연달아 수행되지 않도록 방지함.
- Old Generation이 Full 되기 전에 Garbage Collection을 수행하여 Pause Time을 줄임.
이때 Schedule의 작동 방식은 아래와 같다.
- Old Generation의 점유율이 특정 값을 넘으면 Garbage Collection을 수행하도록 설정된다(기본값: 68%).
- Scheduling을 통해 Minor GC와 Full GC가 동시에 발생하지 않도록 조정하며, Initial Mark 단계는 빠르게 완료되어 별도의 Scheduling에서 제외된다.
Incremental Mode of CMS Collector
CMS Collector에서 Concurrent 작업이 큰 실효성을 거두지 못할 경우 Pause Time을 줄이는 효과가 나타나지 않는다.
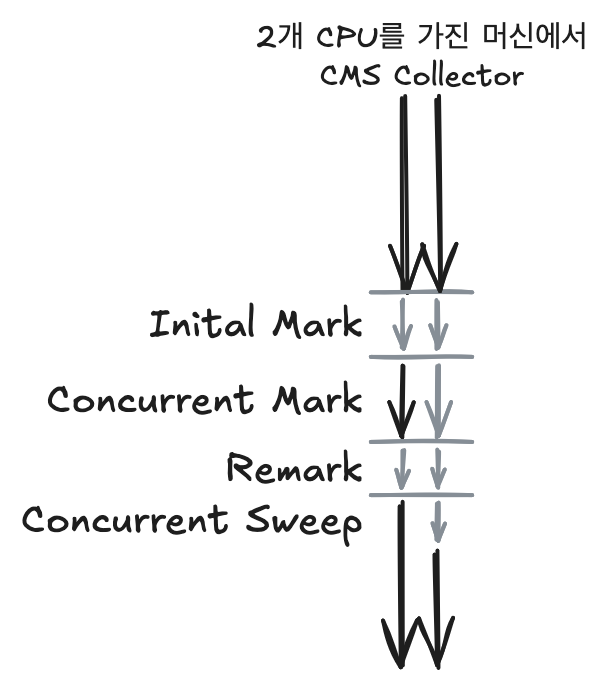
1개의 CPU가 GC Thread에 의해 점유된다는 것이다. 이 경우 Concurrent 작업은 나머지 1개의 CPU에서 수행해야 하므로 Concurrent의 의미가 퇴색될 수 있다.
이 문제를 해결하기 위해 CMS Collector는 Incremental Mode를 지원한다. Incremental Mode는 보다 정교한 Scheduling을 지원하여 Concurrent 작업의 영향을 완화한다. 이를 위해 Concurrent 단계를 작은 시간 단위로 나누어 점진적으로 수행하며, Minor GC와 겹치지 않도록 한다.
또한 Duty Cycle을 설정하여 한 개의 CPU를 점유하는 시간을 제한한다. Duty Cycle은 1개의 CPU를 점유할 수 있는 최대 시간을 의미하며, Minor GC 사이의 시간 비율을 바탕으로 계산된다. Incremental CMS Collector는 기본적으로 Duty Cycle을 자동으로 계산하며, 사용자가 임의로 설정할 수도 있다. 그러나 자동 설정을 권장한다.
Parallel Compaction Collector
Parallel Compaction Collector는 Young Generation에서 Parallel Collector와 동일한 Parallel Copy Algorithm을 사용한다. 그러나 Old Generation에서는 Parallel Compaction Algorithm을 추가하여 사용하는 것이 큰 특징이다.
Old Generation : Parallel Compaction 알고리즘
Parallel Compaction 알고리즘은 3단계로 나누어 수행된다.
- Mark 단계는 Reachable Object를 구별하여 체크한다.
- Summary 단계는 Mark 단계로 Compaction의 일량을 산정하는 단계이다.
- Compaction 단계는 Summary된 데이터를 기반으로 Compaction을 수행한다.
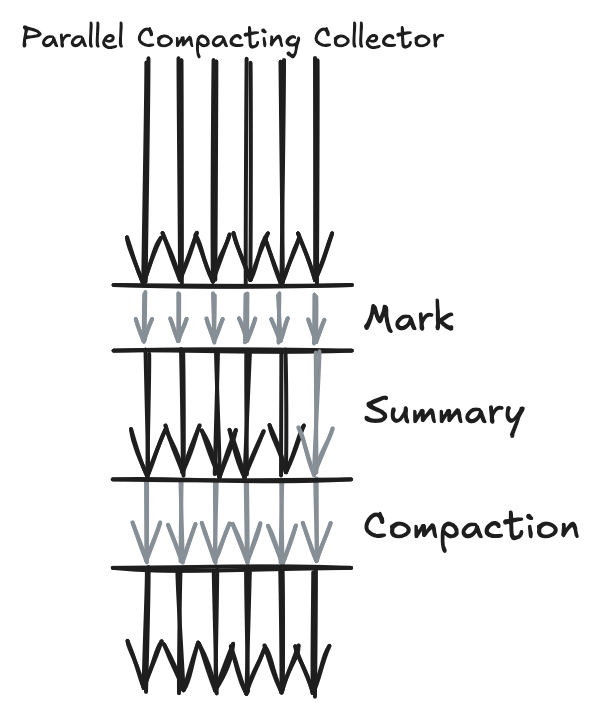
Mark 단계는 Old Generation을 Region이라는 단위로 나누어 병렬 작업으로 수행하는 단계다. 각 Region에서 Live Object를 표시하고, 이 과정에서 객체 크기와 위치 정보가 갱신된다.
Summary 단계에서는 단일 스레드가 GC를 수행하며, 나머지 스레드는 애플리케이션을 실행한다. 이 단계에서는 Region 단위로 밀도(Density)를 평가해 Dense Prefix를 설정한다. Dense Prefix는 도달 가능한 객체가 많은 Region을 구분하는 것으로, 이후 Compaction 단계의 대상을 결정한다. 이로 인해 Compaction 범위가 줄어들어 Garbage Collection 시간이 단축된다.
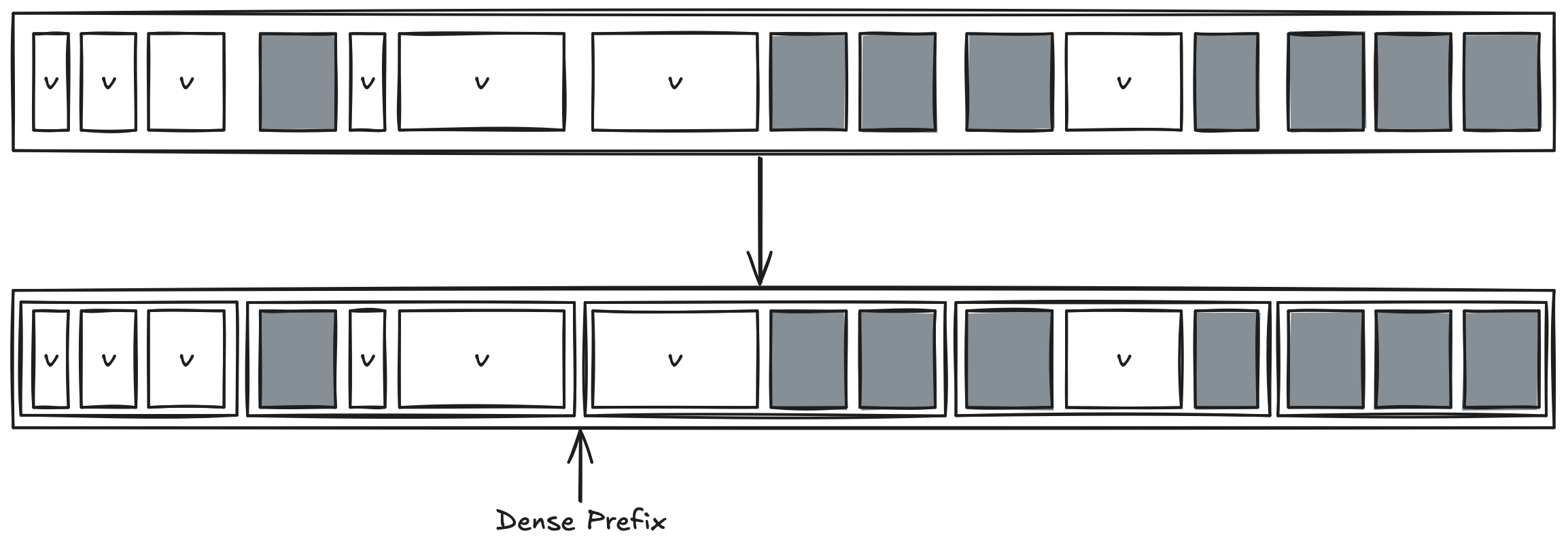
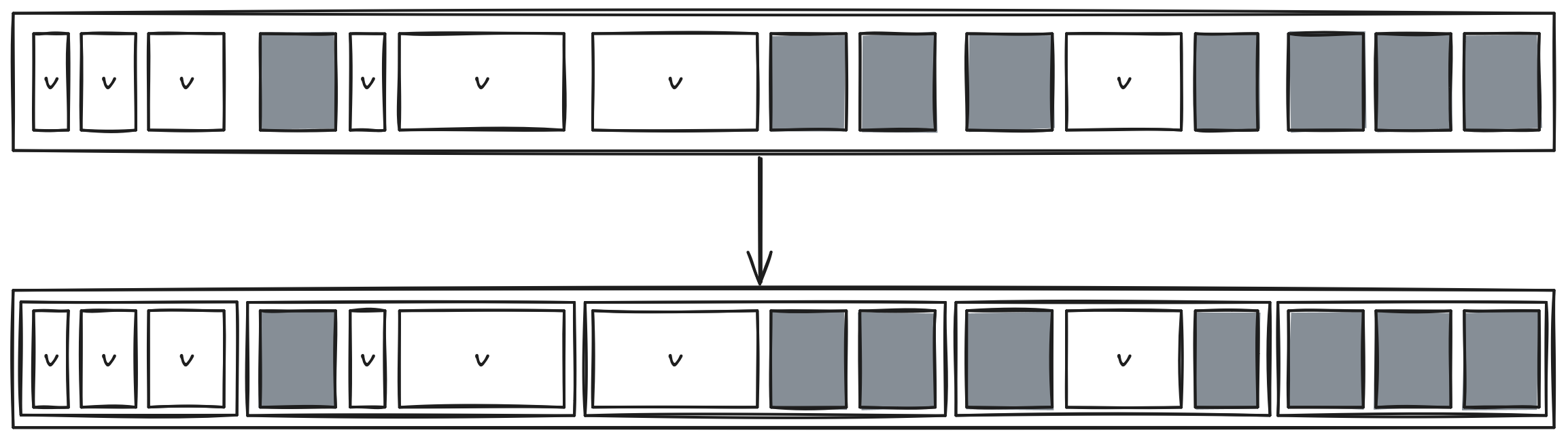
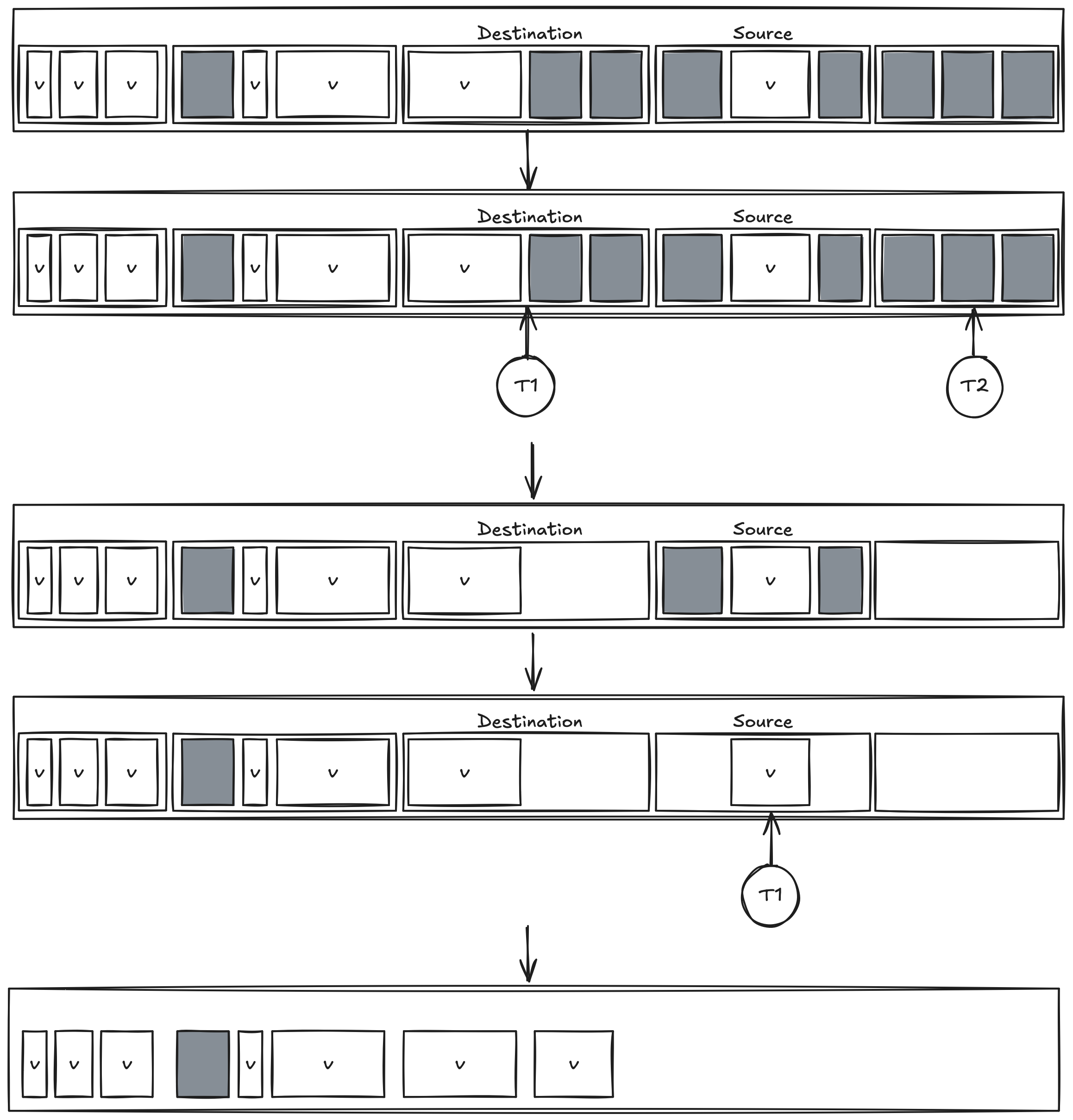
Compaction 단계에서는 Heap을 일시 중지하고 모든 스레드가 Region을 할당받아 Compaction을 수행한다. 이 작업은 Reachable Object를 한쪽으로 이동시키고 Garbage Object를 제거하는 것을 의미한다. 각 스레드는 Destination Region과 Source Region을 구별하여 작업을 진행하며, 결과적으로 Garbage Object가 제거되고 Live Object만 남게 된다.
G1(Garbage First) Collector
G1 Collector는 Hotspot에서 가장 최근에 도입된 가비지 수집기다. Pause Time Goal을 개선하여 CMS Collector보다 예측 가능한 Pause Time을 제공한다는 점이 가장 큰 장점이다.
G1 Collector의 구조
G1 Collector는 기존의 Generation 기반 Collector와 달리 Heap을 Young과 Old Generation으로 나누지 않고 1MB 단위의 Region으로 나누어 관리한다. 이는 메모리 단편화와 Freelist 문제를 해결하고, Stop-The-World 방식의 Compaction 문제를 줄이기 위해 설계되었다.
Garbage First
라는 이름은 Garbage로 가득 찬 Region부터 수집을 시작하기 때문에 붙여졌다. Young과 Old Generation은 물리적 구분이 아닌 Allocation과 Promotion이라는 개념적 구분으로만 존재한다.
다음 그림은 G1 Collector의 Minor GC를 설명한다. 큰 네모는 Heap을 의미하고, 작은 네모는 Region을 나타낸다. 번호 1은 Old Generation의 Region, 번호 2는 Young Generation의 Region, 번호 3은 Young Generation에서 방금 복사된 Survivor Region, 번호 4는 Promotion되어 새로 Old Generation이 된 Region을 의미한다.
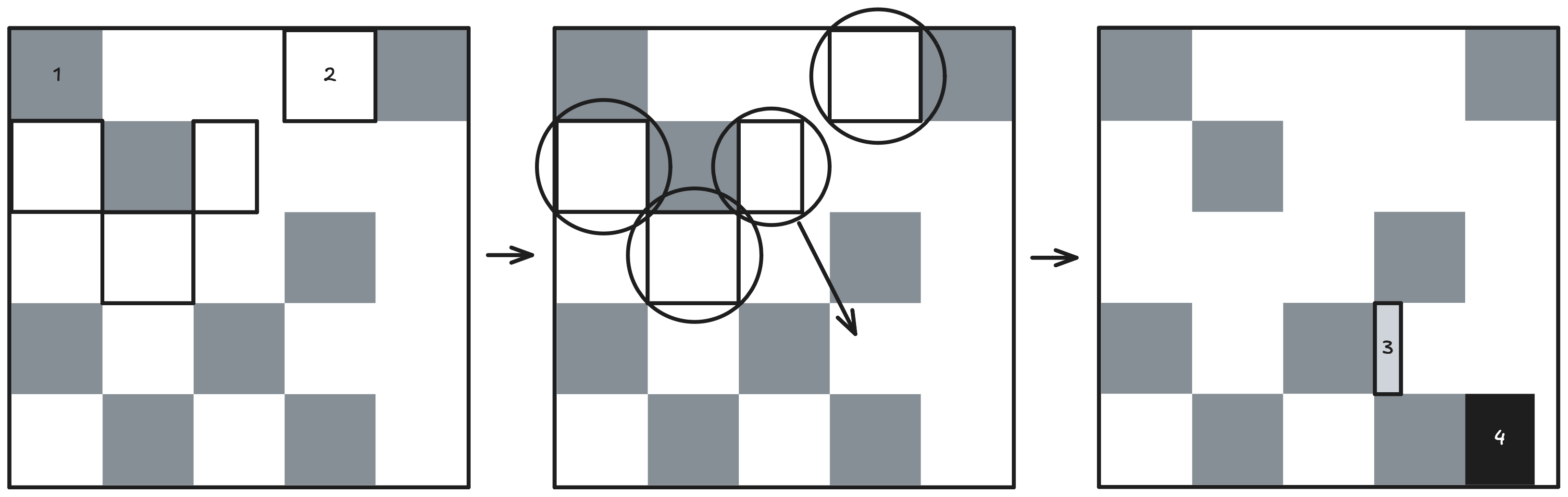
Minor GC가 발생하면 Young Generation의 Region을 대상으로 Reachable Object를 찾아낸 후 Age가 되지 않은 Object는 Survivor Region으로, Promotion 대상 Object는 Old Generation으로 이동한다. 기존의 Young Generation Region은 Garbage로 간주하여 Region 단위로 할당을 해지한다. Young Generation의 GC가 끝나면 바로 Old Generation의 GC가 시작된다.
G1 Collector는 철저하게 Region 단위로 GC가 이루어지므로 Heap 전반에 걸친 GC가 발생하지 않는다. 따라서 GC로 인한 Suspend 현상도 Region을 사용하는 Thread에 국한된다. 이 방법으로 GC의 충격을 최소화한다.
G1 Collector는 Region 내의 Reference를 관리하기 위해 Train Algorithm에서 소개된 Remember Set을 이용한다. 전체 Heap의 5% 미만의 공간을 각 Region의 참조 정보를 저장하는 Remember Set으로 할당한다. Remember Set은 Region의 외부에서 들어오는 참조 정보를 가지고 있어, Marking 작업 시 Trace의 양을 줄여 GC의 효율을 높인다.
Garbage First Collector: Garbage First Collection
기존의 Collector는 Generation별로 알고리즘이 적용되는 방식이었으나, G1 Collector는 사실상 Generation의 구별이 따로 있지 않다. G1 Collector는 Region 단위로 GC가 발생하기 때문에 전반적인 흐름에 초점을 맞추어 설명하는 것이 적절하다.
G1 Collector의 GC는 크게 4단계로 구분되지만 다음 그림처럼 Concurrent Mark단계와 Old Region Reclaim단계가 Concurrent 단계와 Stop-the-World 단계로 구성되어 있어 세부적으로는 6단계로 구분이 가능하다.
G1 Collection에서 GC가 발생하는 시기는 아직 정확하게 알려져 있지 않다. 그러나 Allocation 때 메모리 압박이 생기거나 임계 값을 넘을 때마다 GC가 발생할 것이다.
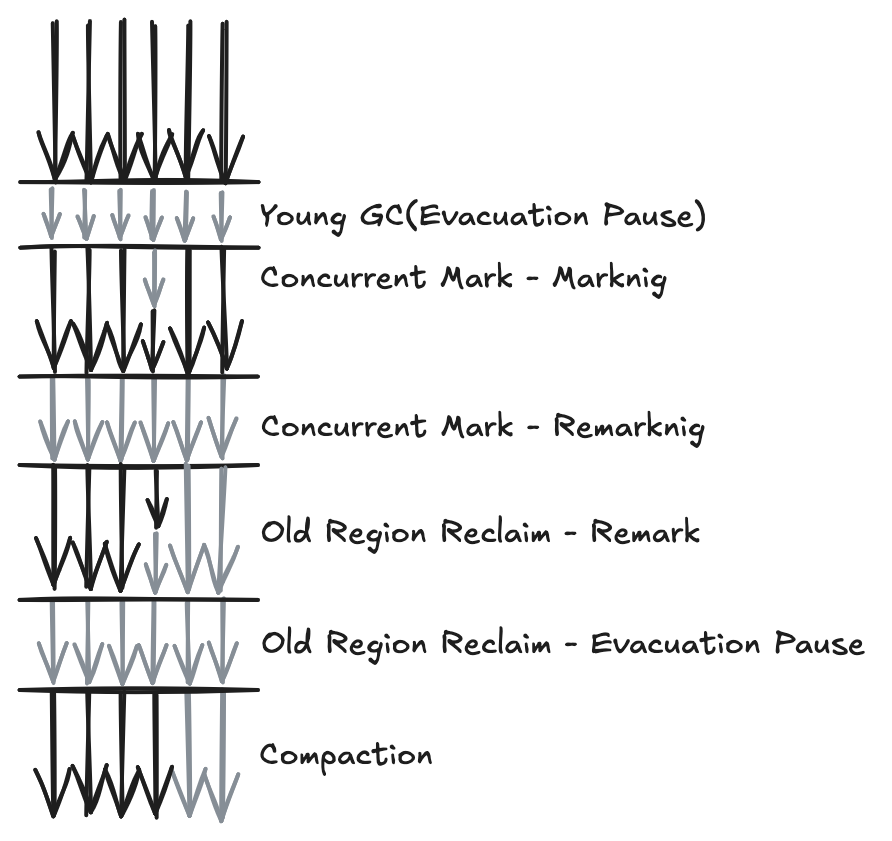
GC는 어떤 이유에서든 Young Generation에서 시작한다. 이 단계를 Young GC (Evacuation Pause)단계라고 한다. 이 단계는 앞서 언급한 Minor GC와 동일하며 Suspend Time이 존재하며 Multi-Thread가 작업하는 Parallel 단계이다. Live Object는 Age에 맞게 Survivor Region과 Old Region으로 복사되고 기존의 공간은 해지된다. 이후 새로운 Object가 할당되는 Young Region은 Survivor Region과 그 근처의 비어있는 Region이 된다. 한마디로 Young Region의 물리적 위치가 변경되는 것이다. 이 단계가 끝나면 Old Region을 대상으로 하는 GC 작업이 이루어진다.
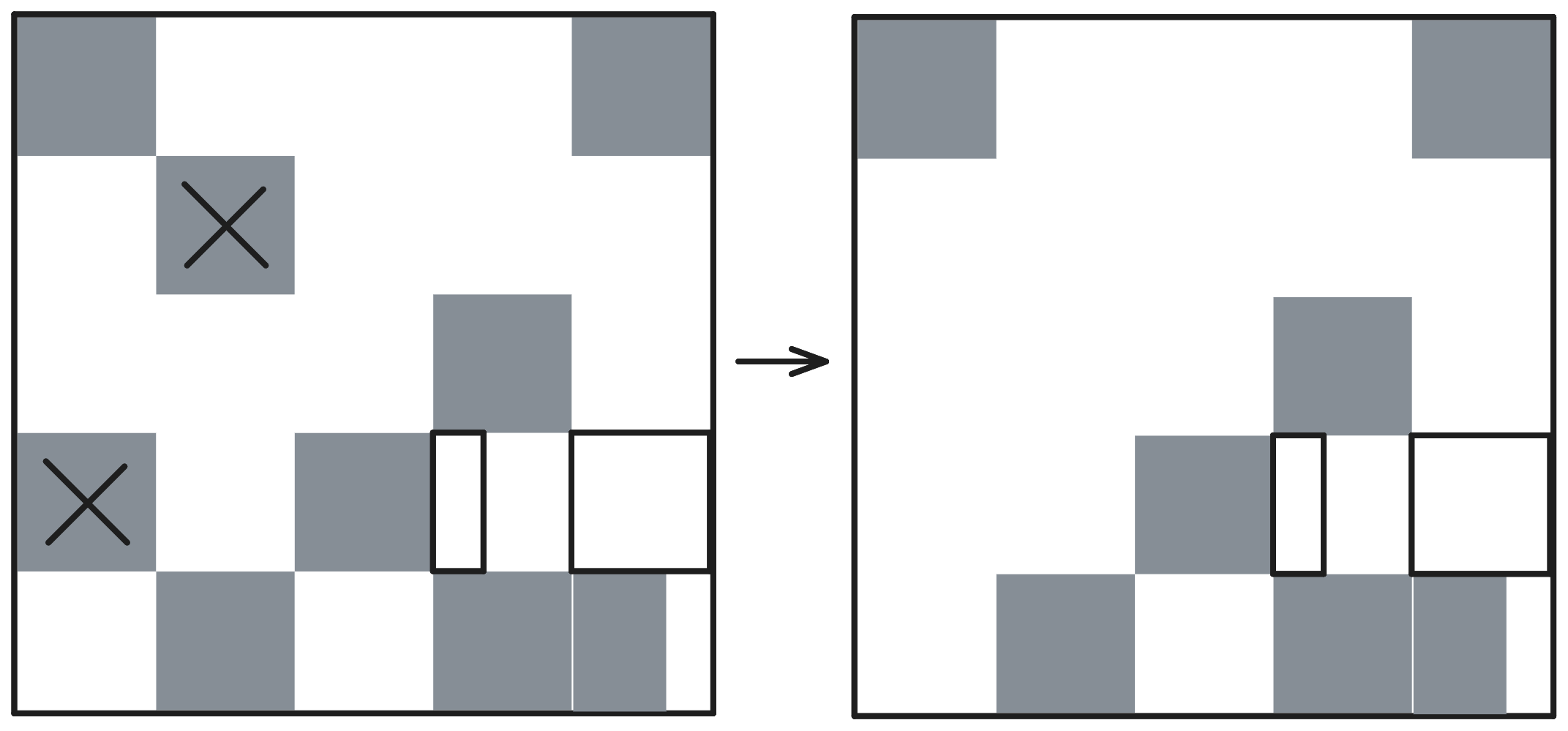
다음 단계는 Concurrent Mark 단계이다. 이 단계는 Marking과 Remarking으로 구분된다. Marking 단계는 Single Thread가 전담하며 전체적으로 Concurrent하게 작업을 수행한다. 이전 단계인 Evacuation 단계에서 변경된 정보를 바탕으로 Initial Mark를 빠르게 수행한 뒤 Remarking 단계로 넘어간다. 이 작업은 Suspend 시간을 가지며 전체 Thread가 함께 참여한다. 각 Region마다 Reachable Object의 Density를 계산한 후 Garbage Region은 다음 단계로 넘어가지 않고 바로 해지된다. 다음의 그림은 Marking 단계에서 Garbage Region으로 판명된 Region을 Remaking 단계에서 삭제하는 것을 보여준다. Remark 단계는 CMS의 동일한 과정보다 더 빠르게 진행된다.
Concurrent Mark 단계에서는 기존 방식과는 다른 Snapshot-At-The-Beginning (SATB)라는 Marking 알고리즘을 사용한다. 이는 GC가 시작할 당시의 Reference를 기준으로 모든 Live Object의 Reference를 추적하는 방식이다. 그러나 Mark 작업은 Concurrent 단계이기 때문에 Reference가 계속해서 변경된다. G1 Collector는 이 작업을 위해 Write Barrier를 이용해 각 Reference의 생성과 분리를 기록한다. 이 기록들은 Garbage Collection이 시작할 때 만들어진 Snapshot과 비교되어 Marking 작업을 빠르게 수행하도록 한다.
Concurrent Mark 단계 이후에는 Old Region Reclaim단계로 넘어간다. 이 단계도 Remark와 Evacuation 단계로 나뉜다. Remark 단계는 Concurrent 작업을 수행하지만 Multi-Thread 방식으로 동작한다. 이 단계에서는 Live Object의 비율이 낮은 Region 중 몇 개를 골라내는 작업을 수행한다.
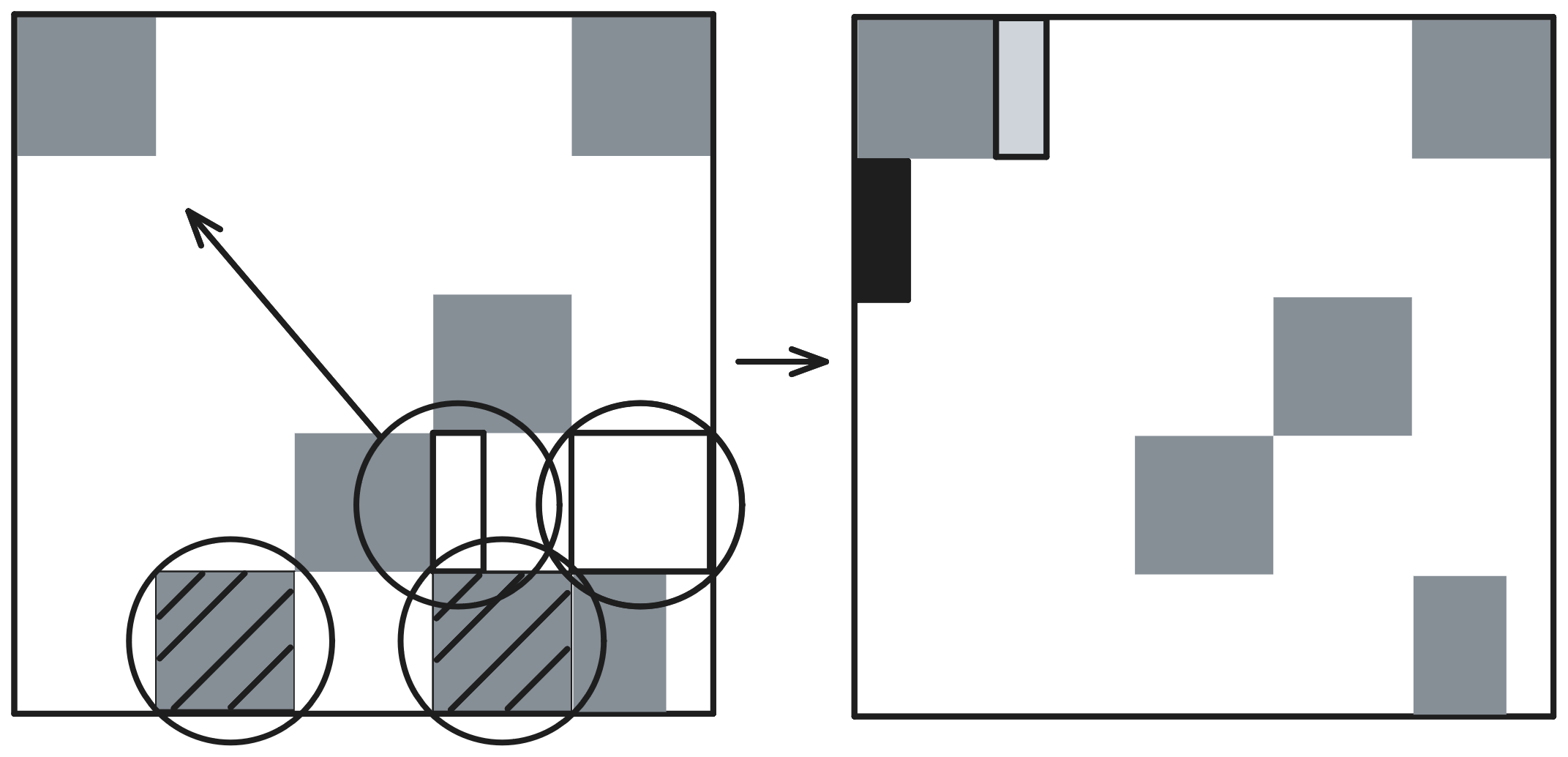
Evacuation 단계는 독특하게도 Young Region에 대한 GC를 포함한다. 앞서 Remark 단계에서 골라낸 Old Region은 Young Region과 같은 방식으로 Evacuation 과정에 동참하게 된다. 그림에서 나타난 것처럼 큰 원으로 표시된 Region들이 Evacuation의 대상이 되는 것들이다. 이 중 하얀 빗금 표시가 되어 있는 Region들은 Old Region이고 나머지는 Young Region이다. 이 Young Region은 Garbage Collection의 첫 단계인 Young GC (Evacuation) 단계 결과로 생성된 Survivor Region과 그 근방의 Empty Region들에 Object가 Allocation되어 생긴 Region들이다.
여기에 Remark에서 선택된 Old Region들까지 Evacuation 단계에서 같이 GC된 것이다. 그 결과 좌측 상단으로 Survivor Region과 Old Region이 하나 생성되었다. Old Region Reclaim 단계가 끝난 이후 Heap에는 몇 개의 Garbage Object만이 존재하는 비교적 Live Object의 Density가 높은 Region들만이 남아 있게 된다. 그러나 이들 또한 시간이 지남에 따라 언젠가는 GC 될 운명에 처하게 된다.
G1 Collector의 마지막 단계는 Compaction단계이다. 이 작업은 다른 Compaction과 달리 Concurrent하게 수행되며 Region 단위로 작업을 수행하기 때문에 가능하다. Compaction의 주된 목적은 Large Chunk로 Free Space를 병합하여 메모리 단편화를 방지하는 것이다. 이는 많은 수의 Region을 균일하게 조금씩만 사용하는 부작용을 방지하는 것으로 보인다.