05.Execution Engine
16 Aug 2024Execution Engine
ClassLoader를 통해 Class가 JVM에 로드된 후, 프로그램이 실행되기 위해서는 Execution Engine이라는 모듈을 거쳐야 한다. Execution Engine은 로드된 Class의 Bytecode를 실제로 실행하는 역할을 하며, Bytecode에 정의된 명령어 집합을 처리하여 프로그램을 수행한다.
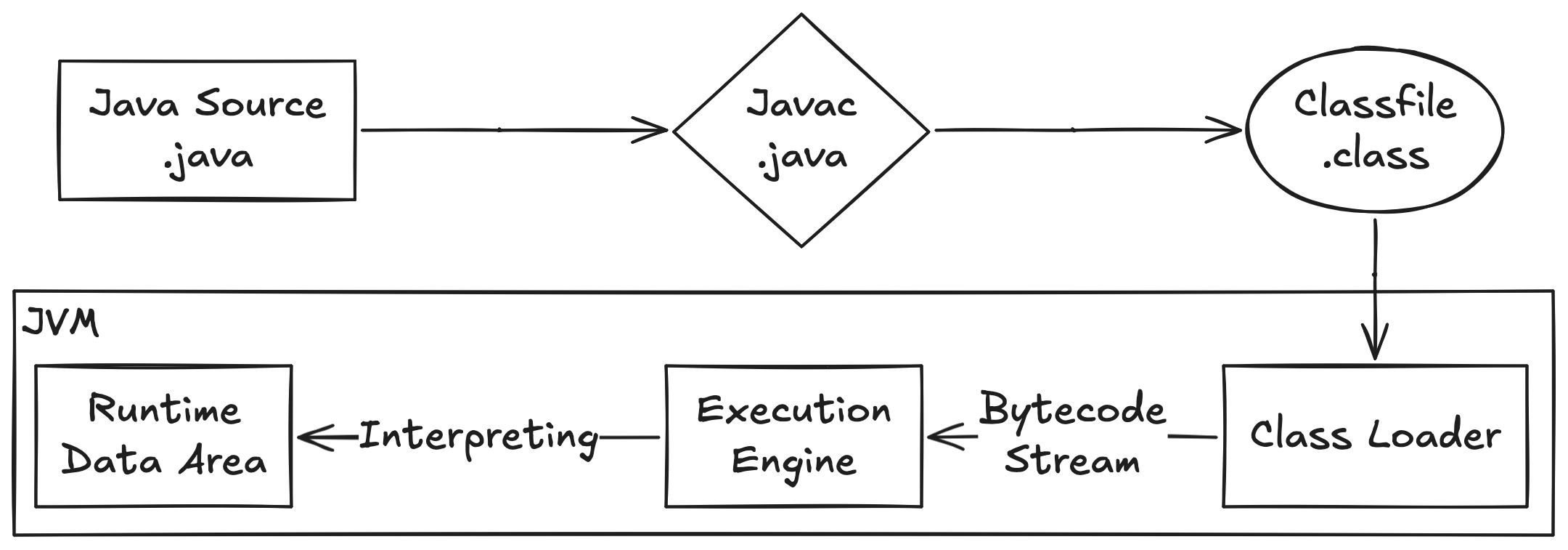
아래 그림은 Java 소스 코드가 JVM에서 실행되는 과정을 간략히 보여준다. 개발자가 작성한 소스 코드는 *.java 파일로 저장된다. 이 파일은 JDK의 javac를 통해 컴파일되어 *.class 파일이 생성된다. 이 Class 파일에는 JVM에서 실행될 Bytecode가 포함되어 있다. JVM은 이 Class 파일을 ClassLoader로 로드하고 링크한 후, Runtime Data Areas의 Method Area에 배치한다. 이후, Execution Engine이 이 Bytecode를 받아 실행한다.
Execution Engine은 소스 코드의 흐름에 따라 Bytecode에 정의된 명령어(Instruction)를 순차적으로 실행한다. 이 명령어는 일반적으로 1바이트의 Opcode와 연산 대상인 Operand로 구성된다.
Execution Engine은 한 번에 하나의 명령어를 처리한다. Opcode를 가져와(Fetch) 지정된 작업을 수행한 후, 다음 Opcode를 가져와 실행하는 방식이다. 예외가 발생할 경우, 적절한 catch 절의 Opcode를 찾아 처리한다.
아래는 간단한 무한 루프를 실행하는 Java 프로그램의 소스 코드와 바이트코드이다. 바이트코드는 사람이 이해하기 쉽게 문자화된 니모닉(Mnemonic)으로 구성되어 있다.
/* Java Source Code */
class neverEnd {
public static void main(String[] args) {
int i = 0;
String A = "String";
for (;;) { // 무한 루프
i = i + 1;
i *= 2;
}
}
}
/* Java Byte Code */
Compiled from "neverEnd.java"
class neverEnd extends java.lang.Object {
neverEnd() {
super();
}
public static void main(java.lang.String[]) {
Code:
0: iconst_0
1: istore_1
2: ldc #2; // String String
4: astore_2
5: iload_1
6: iconst_1
7: iadd
8: istore_1
9: iload_1
10: iconst_2
11: imul
12: istore_1
13: goto 5
}
}
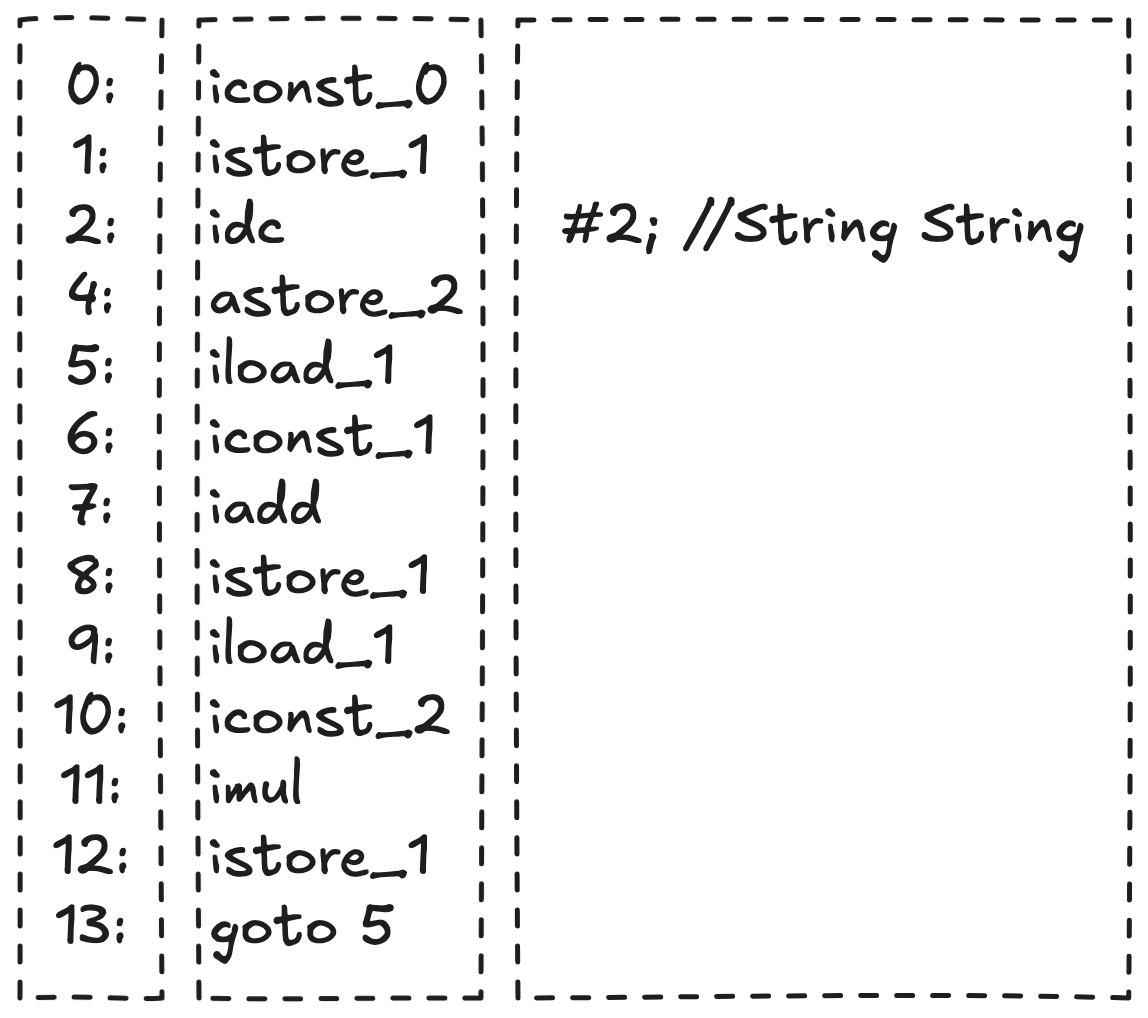
위 바이트코드는 neverEnd 클래스의 일부를 나타낸다. 바이트코드는 크게 세 부분으로 구성된다.
-
Offset: 메서드의 시작 지점으로부터의 오프셋을 나타낸다. 예를 들어,
0:,1:,5:등은 해당 명령어가 메서드 내에서 몇 번째 바이트에 위치하는지를 나타낸다. -
Opcode 및 Operand: 명령어의 니모닉과 작업에 사용되는 상수 또는 번지를 표현한다. 예를 들어,
iconst_0은 정수 0을 스택에 푸시하는 명령어이고,istore_1은 스택에서 값을 꺼내 로컬 변수 1에 저장하는 명령어이다. -
주석: 클래스 실행에 직접적인 영향을 미치지 않지만, 코드의 이해를 돕기 위해 어떤 메서드를 호출하고 있는지를 설명한다. 예를 들어,
ldc #2; // String String에서// String String은 이 명령어가 어떤 상수를 다루고 있는지를 주석으로 설명하고 있다.
이 프로그램은 무한 루프를 도는 예제이므로, 바이트코드에서도 goto 5 명령어를 통해 5번 오프셋으로 계속해서 점프하여 루프를 지속한다.
Execution Engine의 방식
JVM에서 Class가 실행되기 위해서는 Execution Engine이 Bytecode를 해석해야 한다. 하지만 Bytecode는 실제 기계어가 아니라 사람이 이해하기 쉬운 형태로 작성되어 있다. 이 때문에, Execution Engine은 두 가지 방식으로 Bytecode를 해석하여 실행한다.
첫 번째 방식은 Interpreter 방식으로, Bytecode를 한 줄씩 읽어 해석하고 바로 실행한다. 이 방식의 장점은 해석 시간이 짧다는 것이지만, 단점은 실행 속도가 느리다는 점이다.
이를 보완하기 위해 JIT(Just-In-Time) Compiler 방식이 도입되었다. JIT Compiler는 적절한 시점에 Bytecode를 네이티브 코드로 컴파일하여 실행 속도를 높인다. Interpreter가 반복적인 실행을 감지하면 JIT Compiler가 동작하며, 네이티브 코드로 변환된 후에는 실행 속도가 매우 빨라진다. 이 방식은 반복 호출 시 성능을 극대화할 수 있다.
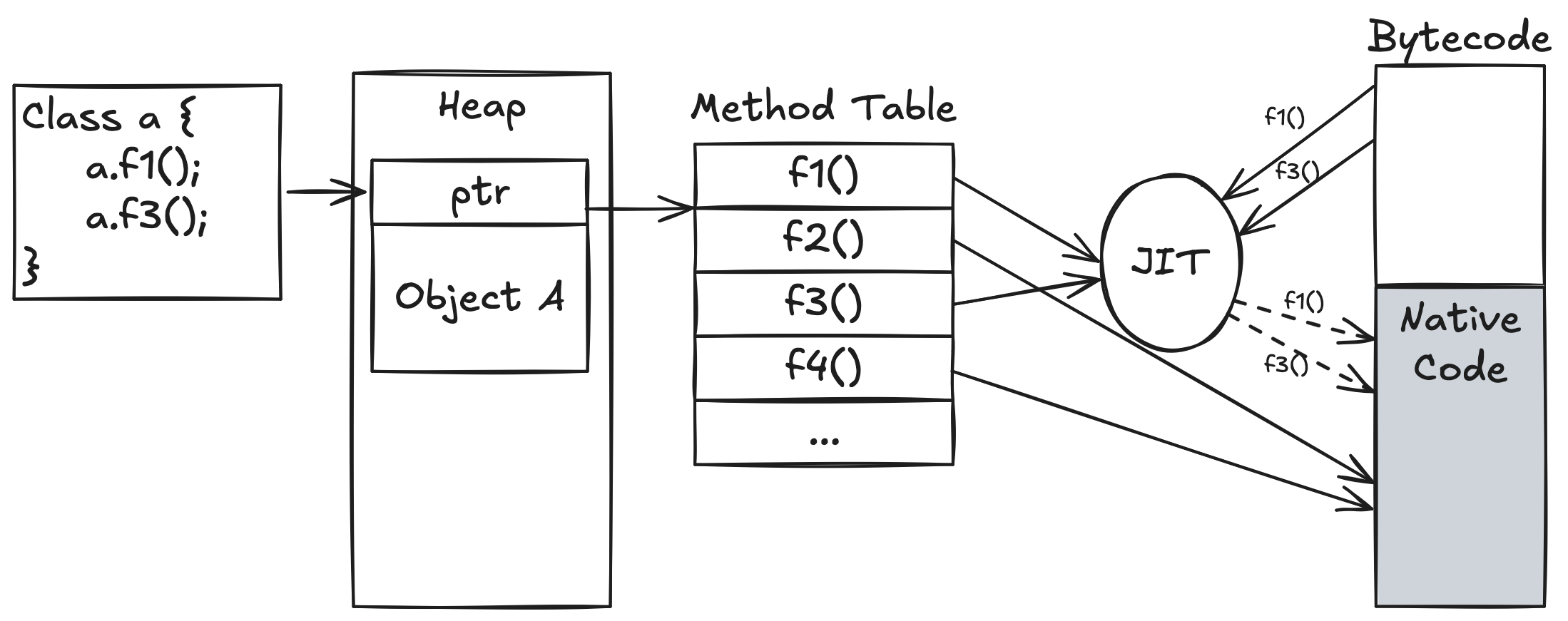
따라서, 현대의 JVM에서는 Interpreter와 JIT Compiler를 혼용하여, 초기에는 Interpreter로 실행하다가 반복적인 작업이 감지되면 JIT Compiler로 전환해 성능을 최적화한다.
Execution Engine의 성능 이슈
초기 JVM은 Interpreter 방식으로 인해 성능 문제가 있었으나, JIT Compiler의 도입으로 성능이 크게 개선되었다. Execution Engine은 애플리케이션의 전체 성능에 큰 영향을 미치며, 현재의 Java는 네이티브 언어에 근접한 속도를 자랑한다. 그러나 여전히 몇 가지 한계가 존재한다.
예를 들어, Loop 문에서 Bytecode를 반복 실행하게 되면 Execution Engine의 작업이 많아져 성능 저하가 발생할 수 있다.
/* 100p-java */
class loop {
void loopmain() {
int a = 0;
for (int i = 0; i < 100; i++) {
a = a + i;
}
}
}
/* loop.class Bytecode */
Compiled from "loop.java"
class loop extends java.lang.Object {
loop() {
super();
}
void loopmain() {
Code:
0: iconst_0
1: istore_1
2: iconst_0
3: istore_2
4: iload_2
5: bipush 100
7: if_icmpge 20
10: iload_1
11: iload_2
12: iadd
13: istore_1
14: iinc 2, 1
17: goto 4
20: return
}
}
또한, Java의 다차원 배열 지원의 한계로 인해 메모리 사용이 비효율적일 수 있다.
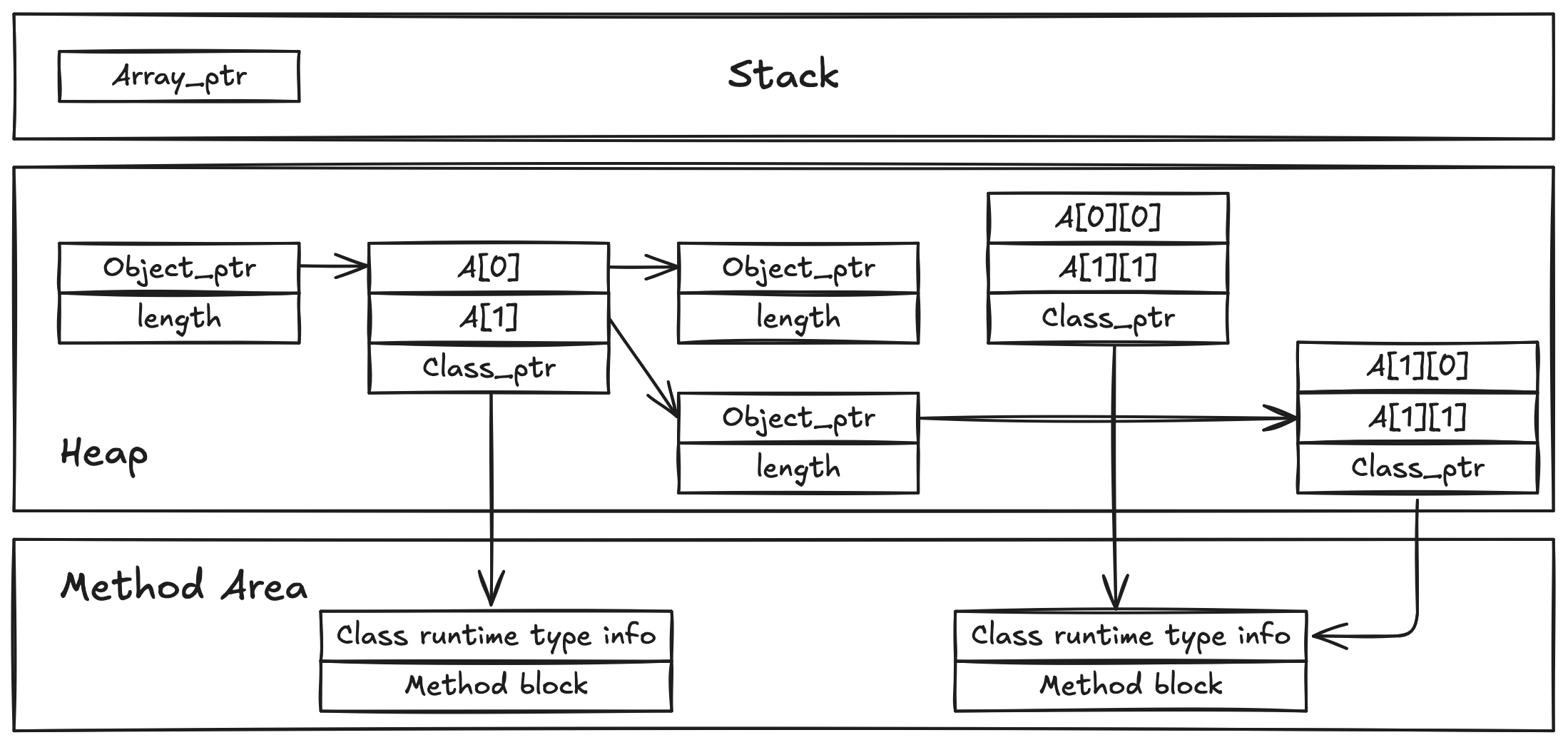
이러한 한계를 극복하기 위해 JVM 벤더들은 다양한 최적화 기법을 적용하고 있으며, Execution Engine의 성능도 지속적으로 개선되고 있다. 예를 들어, IBM JVM은 JIT Compiler를 개선하고, Hotspot JVM은 Hotspot Compiler를 도입하는 등 성능 최적화를 위해 노력하고 있다.
Hotspot Compiler
Hotspot JVM의 이름은 Hotspot Compiler에서 유래되었다. 1.3 버전에서 Hotspot Compiler가 내장된 이후, 이 JVM은 Hotspot JVM으로 불리게 되었다. Hotspot Compiler는 매우 독특하고 강력한 성능을 자랑하며, JVM의 대표적인 컴파일러로 자리 잡았다.
Hotspot이라는 이름은 Hotspot Compiler의 특성에서 기인한다. Hotspot Compiler는 Profiling을 통해 자주 실행되는 Hot Code를 식별하고, 이 코드를 집중적으로 최적화하여 컴파일한다. 이 과정은 불필요한 컴파일을 피하고, 중요한 코드에 최적화를 집중시켜 컴파일 계획을 효율적으로 실행할 수 있게 한다. 즉, 여러 Bytecode 중에서 중요한 Hotspot을 골라내어 최적화하는 컴파일러이기 때문에 Hotspot이라는 이름이 붙은 것이다.
또한, Hotspot Compiler는 Interpreter와 JIT Compiler의 혼합 모드(Mixed Mode System)로 구성되어 있다.
Hotspot Compiler의 동작 방식
Hotspot Compiler의 동작 방식은 아래 그림과 같다.
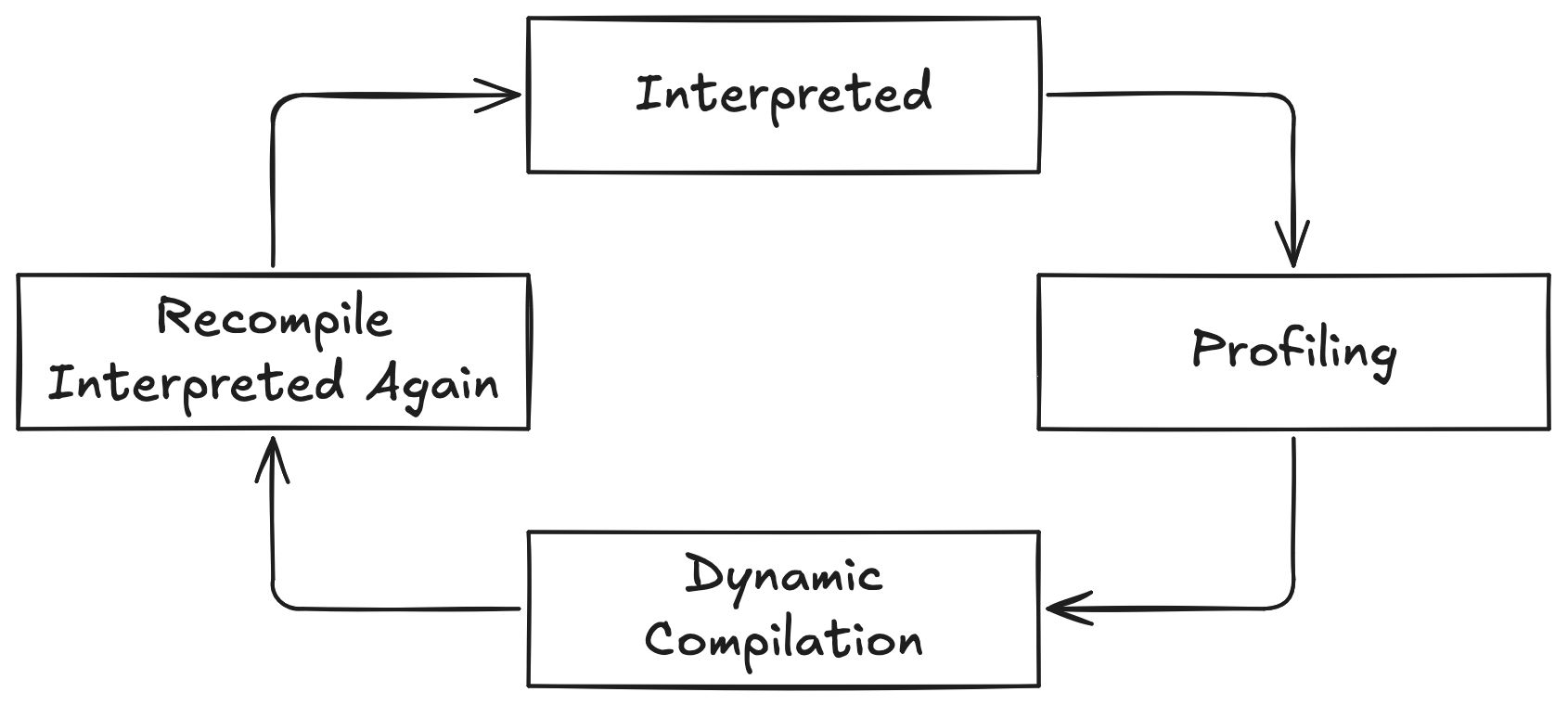
먼저, Bytecode는 Interpreter를 통해 해석되고, Profiling을 거쳐 동적으로 컴파일(Dynamic Compile)된다. 이후 반복적인 사용이 감지되면 재컴파일(Recompile)을 수행한다. 중요한 점은, 만약 사용 횟수가 이전과 같지 않다면 컴파일된 코드를 버리고 다시 Interpreter 모드로 돌아가게 된다는 것이다.
예를 들어, 어떤 메서드가 간헐적으로 집중적으로 수행된 후 한동안 수행되지 않는 경우가 있다고 가정하자. 이러한 경우, 해당 메서드의 네이티브 코드를 계속 캐시하는 것은 메모리의 비효율적인 사용일 수 있다. 이럴 때 Reverse Compile은 성능에 긍정적인 영향을 줄 수 있다.
C1 Compiler
Client VM에서 사용되는 C1 Compiler는 빠르고 가벼운 최적화 과정을 특징으로 하며, 주로 정적인 컴파일을 수행한다. 이 컴파일러는 코드의 패턴을 분석하여 최적화할 대상을 선정하며, Counting Mechanism을 사용해 컴파일할 코드 영역을 결정한다. 대표적인 최적화 기법은 다음과 같다.
-
Value Numbering: 동일한 값으로 반복되는 코드를 축약하여 메모리 사용을 효율적으로 만드는 기법이다.

- Inlining: 메서드 호출을 줄이기 위해, 호출되는 메서드의 코드를 호출 지점에 직접 삽입하는 기법이다. 이를 결정하기 위해 Class Hierarchy Analysis (CHA)를 사용하여 클래스의 계층 구조를 분석한다.
- Global Optimization:
Bytecode를 중간 표현(Intermediate Representation, IR)으로 변환하여 최적화를 수행하는 기법이다. 이 IR은 주로Control Flow Graph (CFG)와Static Single Assignment (SSA)로 구성된다. SSA는 모든 변수가 한 번만 값이 할당되도록 하여 코드를 단순화하고, CFG는 코드 실행 흐름을 그래프로 표현하여 분석을 용이하게 한다.
이러한 최적화 기법을 통해 C1 Compiler는 실행 성능을 향상시키며, 가벼운 애플리케이션에 적합한 컴파일 환경을 제공한다.
C2 Compiler
Server VM에서 사용되는 C2 Compiler는 고수준의 중간 표현(IR)을 생성하며, 데이터와 제어 흐름을 분석해 최적화를 수행하는 강력한 컴파일러이다. IR은 Static Single Assignment (SSA) 형태로 구성되며, 이는 변수에 단 한 번만 값을 할당해 코드의 분석과 최적화를 쉽게 만든다. C2 Compiler는 Profiling Mechanism을 통해 최적화할 대상을 선정하며, 다양한 기법을 통해 성능을 극대화한다. 대표적인 최적화 기법은 다음과 같다.
- Common Sub-Expression Elimination: 반복적으로 수행되는 동일한 계산식을 한 번만 계산하고 그 결과를 재사용하는 기법이다.
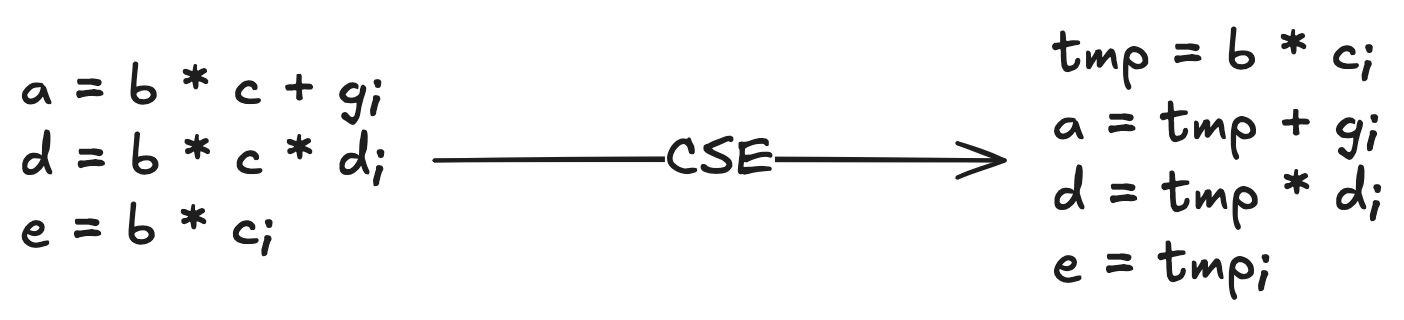
- Loop Unrolling: 반복문의 반복 횟수를 줄여서 성능을 개선하는 기법이다.

- On Stack Replacement: 실행 중인 코드를 동적으로 컴파일된 코드로 교체하여 성능을 향상시키는 기법이다.
public class OnStackReplace { public static void main(String[] args) { long before = System.currentTimeMillis(); int sum = 0; for (int i = 0; i < 10 * 1000 * 1000; i++) { sum += Math.sqrt(i); } long after = System.currentTimeMillis(); System.out.println("Elapsed Time: " + Long.toString(after - before) + " (ms)"); System.out.println("Sum: " + Integer.toString(sum)); } } - Array-Bounds Check Elimination: 배열 접근 시 경계 검사를 생략하여 성능을 높이는 기법이다.
- Dead Code Elimination: 사용되지 않는 코드를 제거하여 실행 효율을 높이는 기법이다.
public class KillDeadCode { public static void main(String[] args) { long before = System.currentTimeMillis(); int sum = 0; // Dead Code for (int i = 0; i < 10 * 1000 * 1000; i++) { sum += Math.sqrt(i); } // Dead Code // Dead Code // Dead Code long after = System.currentTimeMillis() - before; System.out.println("Elapsed Time: " + Long.toString(after) + " (ms)"); } } - Code Hoisting: 반복문 내에서 동일한 값을 가지는 코드를 반복문 밖으로 이동시켜 실행 효율을 높이는 기법이다.

- Data Flow Analysis: 프로그램 내 데이터 흐름을 분석하여 최적화를 수행하는 기법이다.
- Deoptimization: 컴파일된 코드가 더 이상 자주 사용되지 않을 경우 이를 폐기하고, Interpreter 모드로 전환해 자원을 효율적으로 사용하는 Hotspot Compiler만의 독특한 기능이다.
Hotspot Compiler는 이러한 다양한 최적화 기법을 활용하여 Java 애플리케이션이 빠르고 효율적으로 실행되도록 돕는다.